Huffman Coding


Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
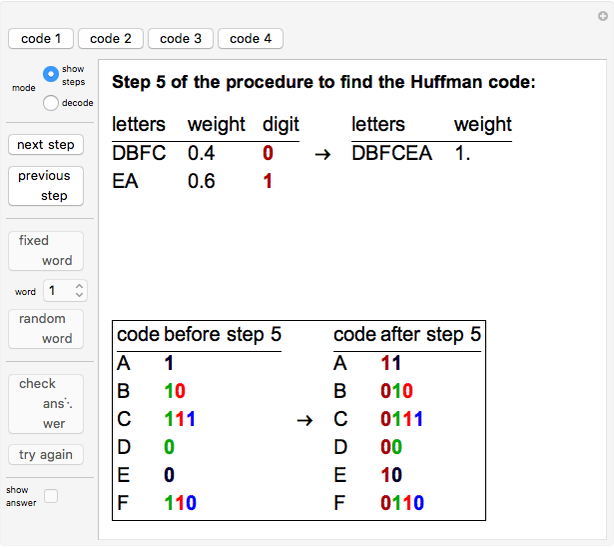
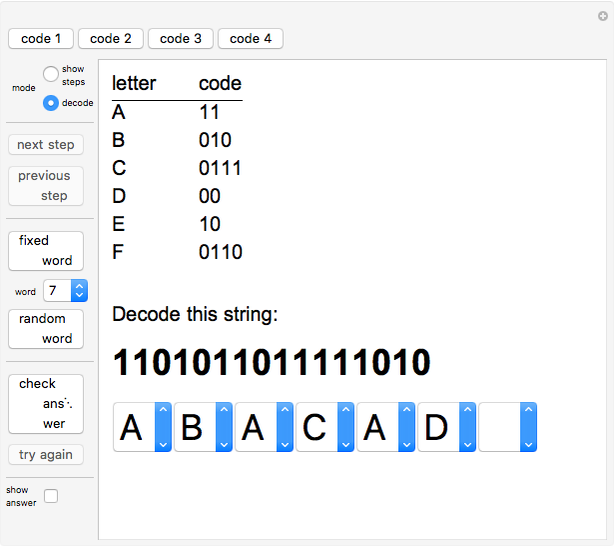
Huffman coding is a method of data compression that assigns shorter code words to those characters that occur with higher probability and longer code words to those characters that occur with lower probability. A Huffman code is an example of a prefix code—no character has a code word that is a prefix of another character's code word. In the "show steps" mode, this Demonstration illustrates the step-by-step procedure for finding the Huffman code for a set of characters with given probabilities. The "decode" mode gives the user an opportunity to decipher strings that have been encoded using the Huffman code.
Contributed by: Marc Brodie (July 2011)
(Wheeling Jesuit University)
Open content licensed under CC BY-NC-SA
Snapshots
Details
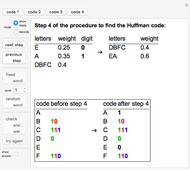
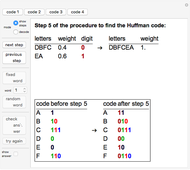
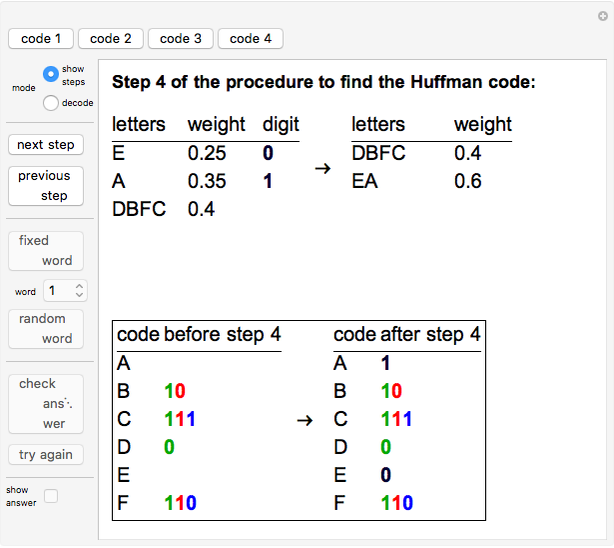
To find the Huffman code for a given set of characters and probabilities, the characters are sorted by increasing probability (weight). The character with smallest probability is given a 0 and the character with the second smallest probability is given a 1. The two characters are concatenated, and their probabilities added. This new string and its weight then take the place of both characters and their weights. At each stage the newly assigned 0's and 1's are prepended to the code strings already assigned to each letter in the corresponding string. This procedure is iterated until there is only one string with weight 1 (see the thumbnail and snapshots 1 and 2).
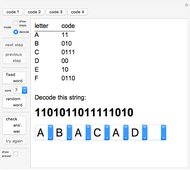
Four different codes are provided. All use the six characters A–F, but have different probabilities assigned to the characters. In the decode mode, nine fixed words are included to make it easy to illustrate the different code words that the different codes give. The random word option will give a random string of length between 3 and 7, inclusive.
Use the popup menus to enter a "guess" for decoding a string.
Permanent Citation
 The Hamming(7,4) Code
The Hamming(7,4) Code
Jacob A. Siehler Mixed Base Gray Codes
Mixed Base Gray Codes
Michael Schreiber Elementary Cellular Automaton Rules by Gray Code
Elementary Cellular Automaton Rules by Gray Code
Michael Schreiber UPC Bar Code
UPC Bar Code
Marc Brodie The POSTNET Bar Code
The POSTNET Bar Code
Marc Brodie Huffman Encoding
Huffman Encoding
Abigail Nussey Shannon's Noisy-Channel Coding Theorem
Shannon's Noisy-Channel Coding Theorem
Hector Zenil and Elena Villarreal Create Your Own Quick Response Code
Create Your Own Quick Response Code
Oliver Jennrich Balanced Ternary Notation
Balanced Ternary Notation
Ed Pegg Jr Finite Field Tables
Finite Field Tables
Ed Pegg Jr
-
 Arranging Balls into Boxes
Arranging Balls into Boxes
Marc Brodie -
 Rotational Symmetries of Colored Platonic Solids
Rotational Symmetries of Colored Platonic Solids
Marc Brodie -
 Arc Length and Polygonal Approximations
Arc Length and Polygonal Approximations
Marc Brodie -
 Subgroup Lattices of Finite Cyclic Groups
Subgroup Lattices of Finite Cyclic Groups
Marc Brodie -
 Venn Diagrams and Syllogisms
Venn Diagrams and Syllogisms
Marc Brodie -
 Crossword Grid Maker
Crossword Grid Maker
Marc Brodie -
UPC Bar Code
Marc Brodie -
 Recognizing Notes in the Context of a Key
Recognizing Notes in the Context of a Key
Marc Brodie -
 Locus of Points Definition of an Ellipse, Hyperbola, Parabola, and Oval of Cassini
Locus of Points Definition of an Ellipse, Hyperbola, Parabola, and Oval of Cassini
Marc Brodie -
 The Music of Mathematical Constants
The Music of Mathematical Constants
Marc Brodie -
 Exploring Relations on Sets
Exploring Relations on Sets
Marc Brodie -
 Subgroup Lattices of Groups of Small Order
Subgroup Lattices of Groups of Small Order
Marc Brodie -
 Math Trivia Game
Math Trivia Game
Marc Brodie -
 The Empirical Rule for Normal Distributions
The Empirical Rule for Normal Distributions
Marc Brodie -
 Geometric Series Based on Equilateral Triangles
Geometric Series Based on Equilateral Triangles
Marc Brodie -
 Geometric Series Based on the Areas of Squares
Geometric Series Based on the Areas of Squares
Marc Brodie -
 Bulls and Cows
Bulls and Cows
Marc Brodie -
 Rings of Small Order
Rings of Small Order
Marc Brodie -
 Counting Necklaces
Counting Necklaces
Marc Brodie -
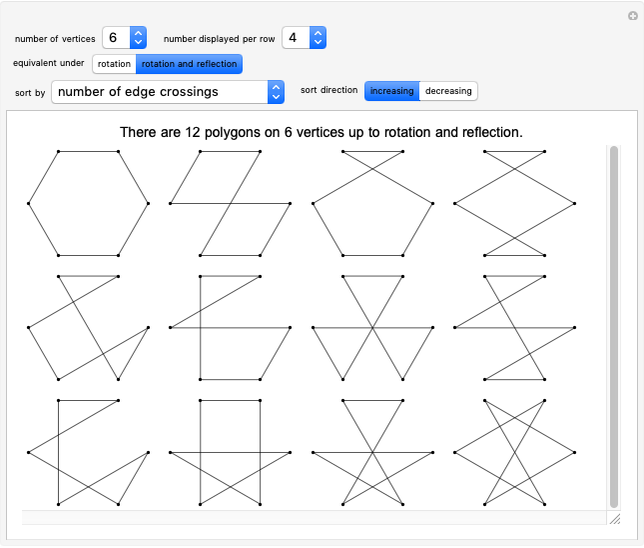 Polygons on n Vertices
Polygons on n Vertices
Marc Brodie