Local Minimum Using SGD, ADAM, OGR Gradient Descent Optimizers

Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
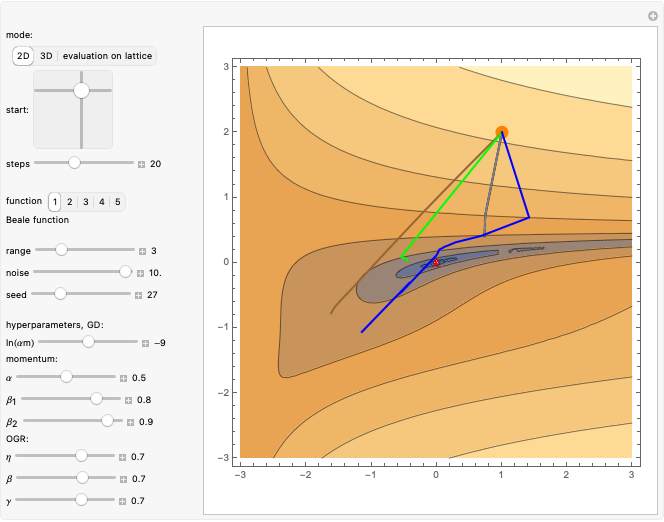
Finding a local minimum, possibly using the Wolfram Language FindMinimum function, is a basic numerical problem at the heart of neural network training. Finding a local minimum is usually done by calculating gradients at neighboring initial points and descending along them (gradient descent). The object is then to optimize convergence speed. Calculated gradients are often inaccurate (simulated here by adding Gaussian noise), suggesting the use of some averaging procedure (e.g. the momentum method).
[more]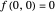
Contributed by: Jarek Duda (June 13)
Open content licensed under CC BY-NC-SA
Details
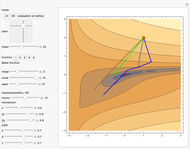
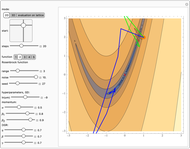
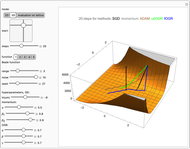
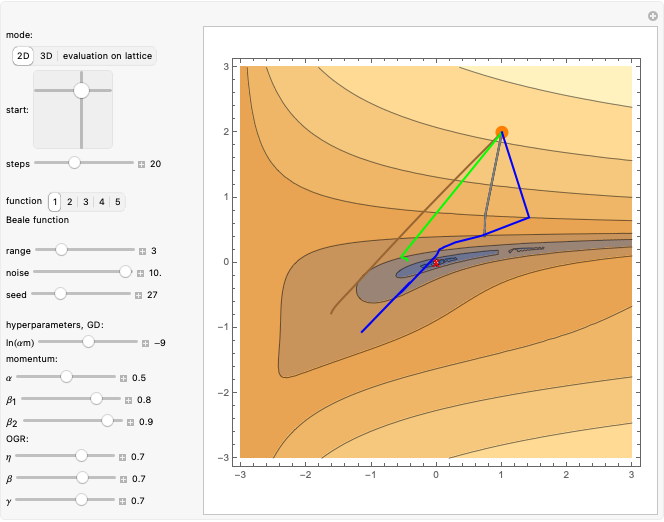
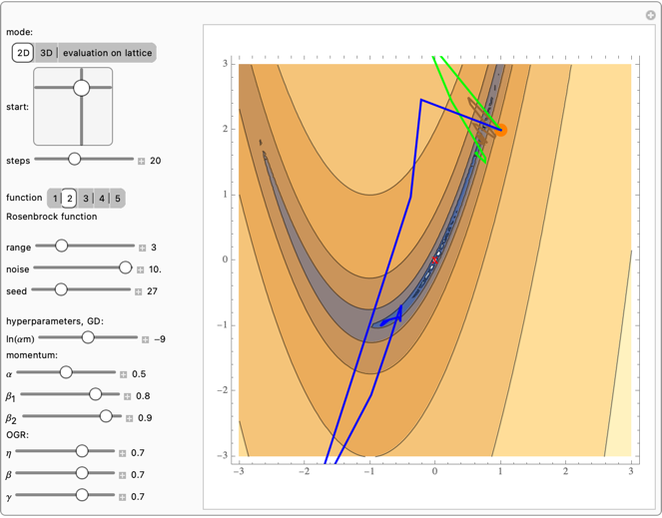
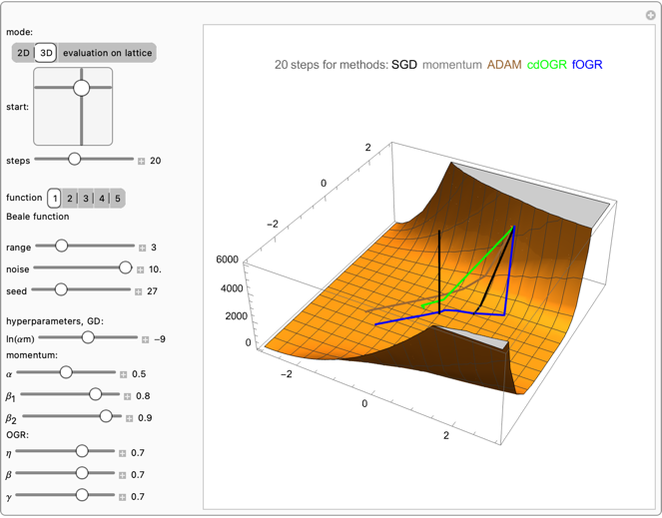
Use the "mode" buttons to choose 2D or 3D view of trajectories. Evaluation is shown on sorted values from 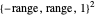 lattice of initial points.
lattice of initial points.
Use the 2D slider "start" to choose the starting point.
The "steps" slider sets the number of steps used for all methods.
Use the "range" slider to set the range shown in 2D and 3D plots and the lattice of starting points in evaluation mode. To prevent escape to infinity, positions are enforced to be in a ball of radius 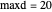 .
.
Use the "noise" slider to control standard deviation of random Gaussian noise added to the gradient.
Use the "seed" slider to choose the random number generator seed for this noise.
Then you can choose one of five popular 2D test functions from [1], which were shifted to have 0 minimum in (0,0), marked with a red "X".
Finally, you can tune hyperparameters of the methods to investigate their dependence. Source code prevents very large steps in ADAM or OGR.
Vanilla SGD uses only "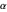 mom" learning rate; momentum additionally has gradient averaging—with adaptation rate controlled by
mom" learning rate; momentum additionally has gradient averaging—with adaptation rate controlled by 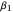 . ADAM uses "
. ADAM uses "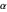 " learning rate and "
" learning rate and "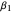 ", "
", " " adaptation rates.
" adaptation rates.
OGR has " " similar to the learning rate, for which
" similar to the learning rate, for which 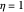 would mean jumping to the modeled minimum of a parabola. It has also two adaptation rates: "
would mean jumping to the modeled minimum of a parabola. It has also two adaptation rates: "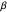 " for averaged gradient in Newton step, and "
" for averaged gradient in Newton step, and "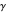 " for the Hessian estimator. We could assume
" for the Hessian estimator. We could assume 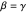 , simplifying and reducing computational cost; however, for generality, they are separated here, with the suggestion to use
, simplifying and reducing computational cost; however, for generality, they are separated here, with the suggestion to use 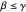 .
.
References
[1] Wikipedia. "Test Functions for Optimization." (Mar 7, 2023) en.wikipedia.org/wiki/Test_functions_for_optimization.
[2] S. Ruder. "An Overview of Gradient Descent Optimization Algorithms." (Mar 7, 2023) www.ruder.io/optimizing-gradient-descent.
[3] J. Duda, "Improving SGD Convergence by Online Linear Regression of Gradients in Multiple Statistically Relevant Directions." arxiv.org/abs/1901.11457.
[4] JarekDuda. "SGD-OGR-Hessian-estimator." (Mar 7, 2023) github.com/JarekDuda/SGD-OGR-Hessian-estimator.
Snapshots
Permanent Citation
 Iterations of Some Algorithms for Unconstrained Local Optimization
Iterations of Some Algorithms for Unconstrained Local Optimization
Heikki Ruskeepää Maximum Sum Descent
Maximum Sum Descent
Heikki Ruskeepää Simple Unconstrained Optimization Method
Simple Unconstrained Optimization Method
Marko Petkovic Ant Colony Optimization (ACO)
Ant Colony Optimization (ACO)
Rasmus Kamper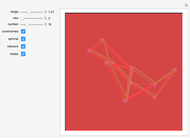 Constrained Optimal Routes in 3D Space
Constrained Optimal Routes in 3D Space
Vitaliy Kaurov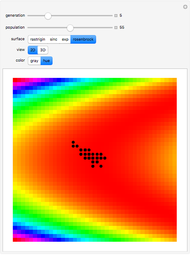 Global Minimum of a Surface
Global Minimum of a Surface
Daniel de Souza Carvalho Greedy Algorithms for a Minimum Spanning Tree
Greedy Algorithms for a Minimum Spanning Tree
Frederick Wu Particle Swarm Optimization for 2D Problems
Particle Swarm Optimization for 2D Problems
Housam Binous, Ahmed Bellagi, Ali Kh. Al-Matar, and Brian G. Higgins The Traveling Salesman Problem 1: Optimal Paths
The Traveling Salesman Problem 1: Optimal Paths
Jaime Rangel-Mondragon Optimal Bin Packing with Random Lengths
Optimal Bin Packing with Random Lengths
Yifan Hu and Stephen Wolfram
-
 Local Minimum Using SGD, ADAM, OGR Gradient Descent Optimizers
Local Minimum Using SGD, ADAM, OGR Gradient Descent Optimizers
Jarek Duda -
 Topological Charges in Biaxial Nematic Liquid Crystal
Topological Charges in Biaxial Nematic Liquid Crystal
Jarek Duda -
 Parametric Density Estimation Using Polynomials and Fourier Series
Parametric Density Estimation Using Polynomials and Fourier Series
Jarek Duda -
 Kepler Problem with Classical Spin-Orbit Interaction
Kepler Problem with Classical Spin-Orbit Interaction
Jarek Duda -
 Electron Conductance Models Using Maximal Entropy Random Walks
Electron Conductance Models Using Maximal Entropy Random Walks
Jarek Duda -
 MU-MIMO Beamforming by Constructive Interference
MU-MIMO Beamforming by Constructive Interference
Jarek Duda -
 Separation of Topological Singularities
Separation of Topological Singularities
Jarek Duda -
 Correction Trees
Correction Trees
Jarek Duda -
 Data Compression Using Asymmetric Numeral Systems
Data Compression Using Asymmetric Numeral Systems
Jarek Duda -
 The Boundary of Periodic Iterated Function Systems
The Boundary of Periodic Iterated Function Systems
Jarek Duda -
 Number Systems Using a Complex Base
Number Systems Using a Complex Base
Jarek Duda -
 Number Systems in 3D
Number Systems in 3D
Jarek Duda