Term Weighting with TF-IDF


Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
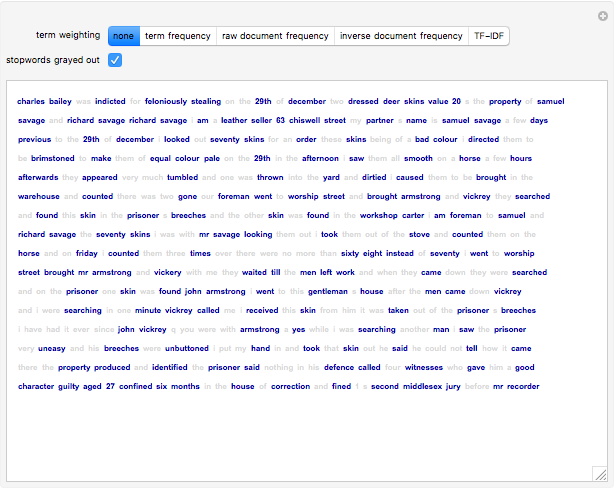
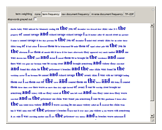
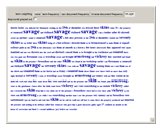
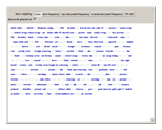
TF-IDF (term frequency-inverse document frequency) is a way of determining which terms in a document should be weighted most heavily when trying to understand what the document is about. The term frequency reflects how often a given term appears in the document of interest. The document frequency is measured with respect to a corpus of other documents. It tells you how often the term appears in your corpus overall. The terms that are most informative about a particular text have a high term frequency and a low document frequency. The TF-IDF for a term is the product of its term frequency and the scaled inverse of its document frequency. Stopwords are those words that occur so frequently in the language that they rarely convey information about the meaning of a particular document. In this Demonstration, stopwords can be turned on and off, and the font size of each term can be scaled by various weighting factors.
Contributed by: William J. Turkel (March 2011)
Open content licensed under CC BY-NC-SA
Snapshots
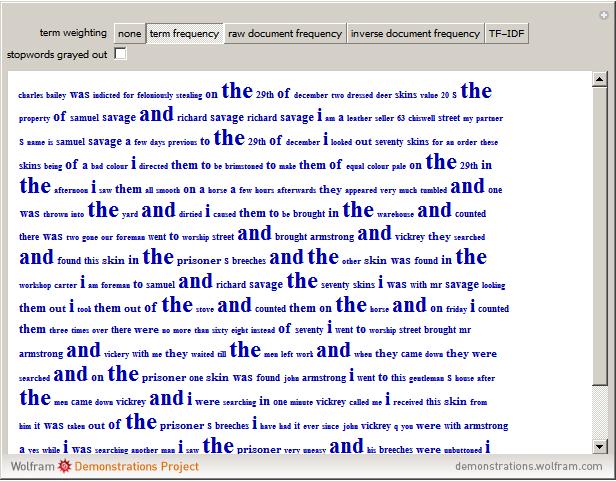
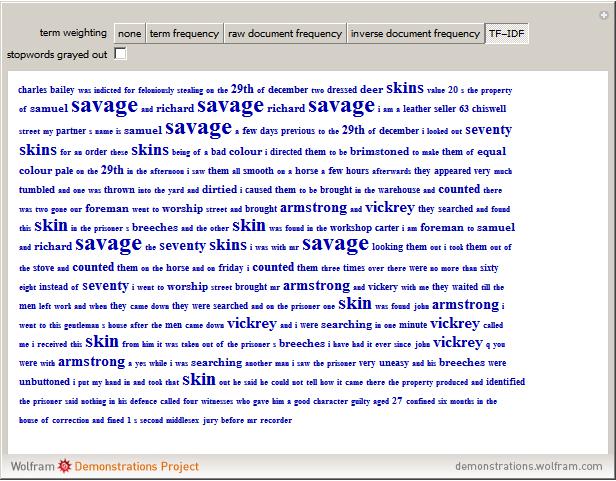
Details
This Demonstration uses Old Bailey Online t18100110-41. The built-in Mathematica function WordData was used to generate a list of stopwords for this Demonstration.
The Old Bailey Online contains digital versions of almost 200,000 criminal trials held at London's central criminal court between 1674 and 1913.
This work is part of the Criminal Intent project, funded by a 2009 Digging into Data challenge grant.
For more about TF-IDF, see [1].
Reference
[1] C. D. Manning, P. Raghavan, and H. Schütze, Introduction to Information Retrieval, Cambridge: Cambridge University Press, 2008.
Permanent Citation
"Term Weighting with TF-IDF"
http://demonstrations.wolfram.com/TermWeightingWithTFIDF/
Wolfram Demonstrations Project
Published: March 7 2011
 Prediction and Entropy of Languages
Prediction and Entropy of Languages
Hector Zenil and Elena Villarreal Shakespearean Networks
Shakespearean Networks
Seth J. Chandler Communities of Nations Bridged by Language Similarity
Communities of Nations Bridged by Language Similarity
Seth J. Chandler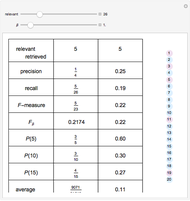 Basic Performance Measures for Information Retrieval
Basic Performance Measures for Information Retrieval
Giovanna Roda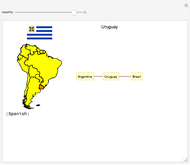 Languages in South American Countries
Languages in South American Countries
Daniel de Souza Carvalho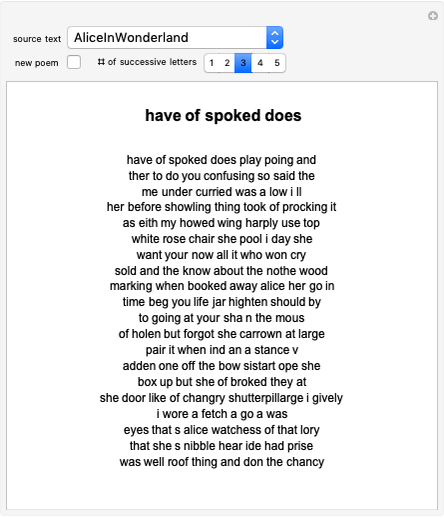 Poem Maker
Poem Maker
William Sethares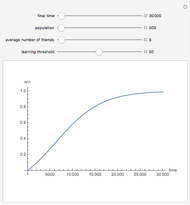 How Long Does It Take a Society to Learn a New Term?
How Long Does It Take a Society to Learn a New Term?
Sadegh Raeisi Scrambled Sentences Builder
Scrambled Sentences Builder
Bianca Eifert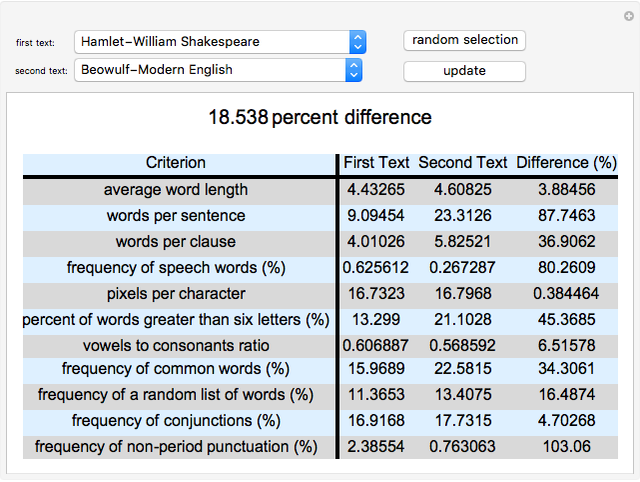 Comparing Writing Styles of Famous Texts
Comparing Writing Styles of Famous Texts
Arkady Arkhangorodsky Book Reader
Book Reader
Jon McLoone