Automatically Selecting Histogram Bins



Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
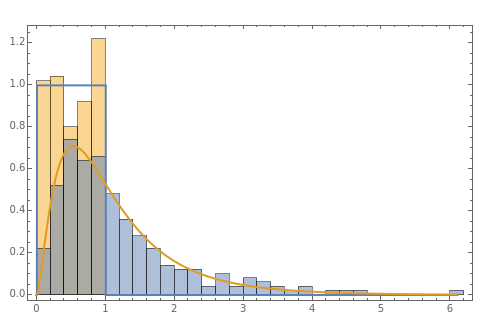
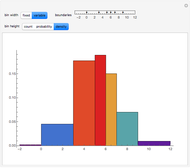
Choosing the bin sizes for a histogram can be surprisingly tricky. If there are too few bins, it is hard to pick out the underlying distribution of the data. If there are too many bins, the result is either unpleasant to look at because the bins have deteriorated into sticks or noise in the data is not sufficiently averaged out, also making it hard to see the underlying distribution. Here we present several methods for selecting (uniform-width) bins for a histogram.
[more]
Contributed by: Brett Champion (December 2008)
Open content licensed under CC BY-NC-SA
Snapshots
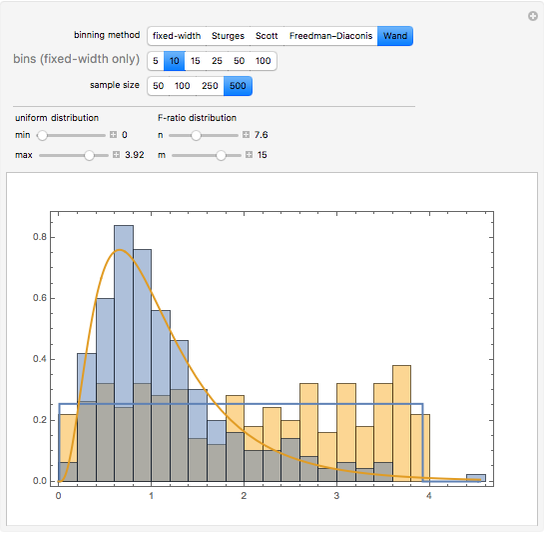
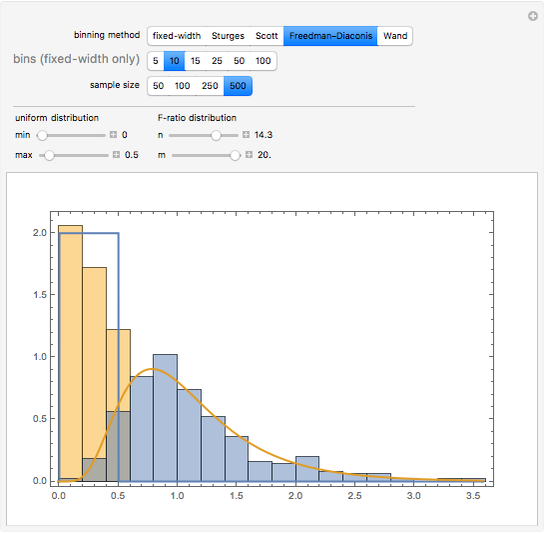
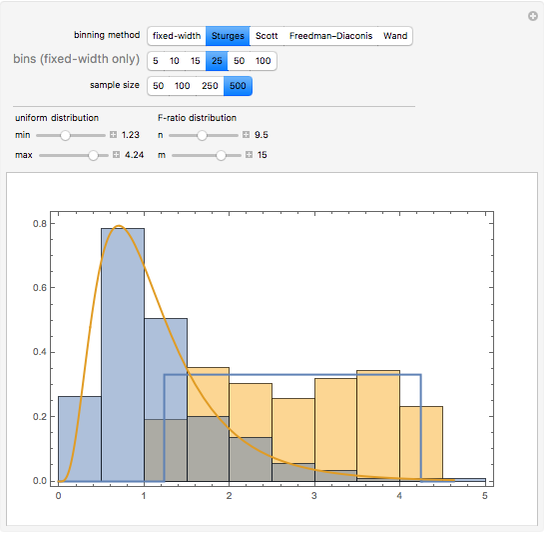
Details
By default Mathematica rounds bin widths to "nice" values, minimizing some of the differences between the various binning methods.
D. Freedman and P. Diaconis, "On the Histogram as a Density Estimator: 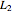 Theory," Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebeite, 57, 1981 pp. 453–476.
Theory," Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebeite, 57, 1981 pp. 453–476.
D. W. Scott, "On Optimal and Data-Based Histograms," Biometrika, 66(3), 1979 pp. 605–610.
H. A. Sturges, "The Choice of a Class Interval," Journal of the American Statistical Association, 21(153), 1926 pp. 65–66.
M. P. Wand, "Data-Based Choice of Histogram Bin Width," The American Statistician, 51(1), 1997 pp. 59–64.
Permanent Citation
"Automatically Selecting Histogram Bins"
http://demonstrations.wolfram.com/AutomaticallySelectingHistogramBins/
Wolfram Demonstrations Project
Published: December 6 2008
 Effects of Bin Width and Height in a Histogram
Effects of Bin Width and Height in a Histogram
Brett Champion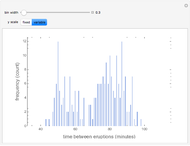 Bin Width and Histogram Shape
Bin Width and Histogram Shape
Jim Brandt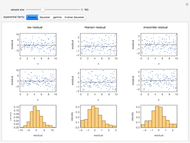 Comparing Some Residuals for Generalized Linear Models
Comparing Some Residuals for Generalized Linear Models
Darren Glosemeyer Matching Temperature Data to a Normal Distribution
Matching Temperature Data to a Normal Distribution
Trevor Cole Exploring Multivariate Data
Exploring Multivariate Data
Danny Turner (Winthrop University)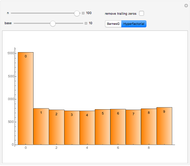 Digits of Hyperfactorial and Barnes G
Digits of Hyperfactorial and Barnes G
Oleksandr Pavlyk Impact of Sample Size on Approximating the Triangular Distribution
Impact of Sample Size on Approximating the Triangular Distribution
Paul Savory (University of Nebraska-Lincoln) Sampling Distribution of the Mean and Standard Deviation in Various Populations
Sampling Distribution of the Mean and Standard Deviation in Various Populations
Ian McLeod Impact of Sample Size on Approximating the Normal Distribution
Impact of Sample Size on Approximating the Normal Distribution
Paul Savory (University of Nebraska-Lincoln) Sequence Alignment of Words
Sequence Alignment of Words
Xiangdong Wen
-
 Chemical Abundances and Properties
Chemical Abundances and Properties
Brett Champion -
 SectorChart Applied to GDP
SectorChart Applied to GDP
Brett Champion -
 Bubble Chart Comparisons of Countries
Bubble Chart Comparisons of Countries
Brett Champion -
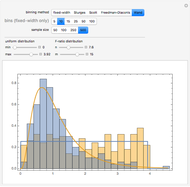 Automatically Selecting Histogram Bins
Automatically Selecting Histogram Bins
Brett Champion -
 Periodic Table in 3D
Periodic Table in 3D
Brett Champion -
 Wilson's Theorem in Disguise
Wilson's Theorem in Disguise
Brett Champion -
Effects of Bin Width and Height in a Histogram
Brett Champion -
 Population Donut Chart
Population Donut Chart
Brett Champion -
 Eggstravaganza
Eggstravaganza
Brett Champion -
 Lines through Points in the Poincaré Disk
Lines through Points in the Poincaré Disk
Brett Champion -
 Circle Intersection Patterns
Circle Intersection Patterns
Brett Champion