Distributions Using Slice Sampling




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
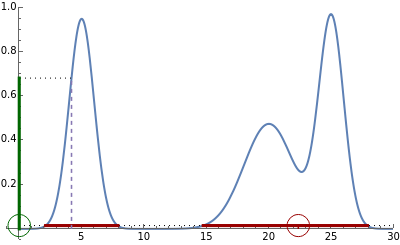
Slice sampling is a Markov chain Monte Carlo method used to sample points from a given distribution. The algorithm may be summarized as follows: given the previously sampled point, indicated by a purple dashed line, the corresponding ordinate is evaluated. A random number is drawn from a uniform distribution from zero to the ordinate value, indicated by a green circle. The intersections of a horizontal line (slice) at this value with the distribution curve is calculated. From the regions where the curve lies above the horizontal line, a second uniformly distributed random value is drawn, indicated by a red circle. This value is taken as the new sample point, and the algorithm repeats using this as the new starting point. A histogram of the sampled points is shown at the bottom. Adjust the slider to view the next or previous sample points. The distribution shapes may be chosen as Gaussian, gamma, or a linear combination of multiple Gaussian or gamma distributions. To generate new random variables for the current sample point, click the "generate random sample" button.
Contributed by: Oliver K. Ernst (July 2015)
Open content licensed under CC BY-NC-SA
Snapshots
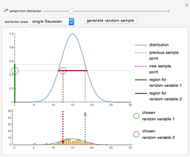
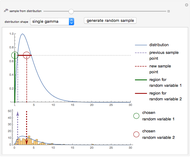
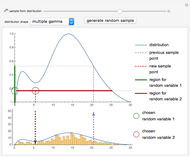
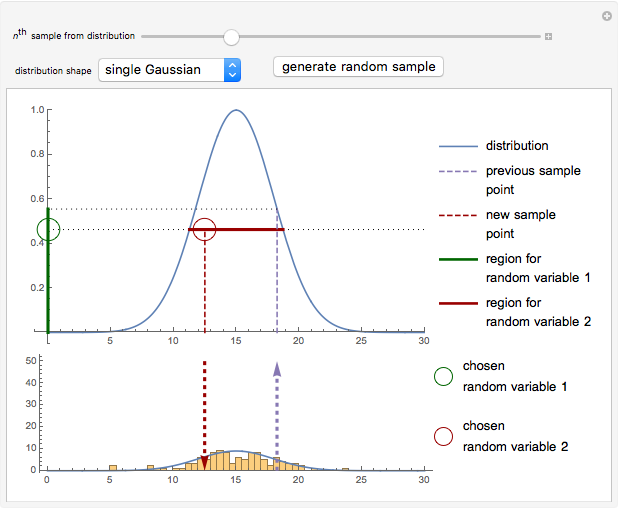


Details
Snapshot 1: sampling from a Gaussian distribution
Snapshot 2: sampling from a gamma distribution
Snapshot 3: sampling from a linear combination of gamma distributions; an example involving divided slices
Consider the problem of drawing samples from an arbitrary distribution. If the cumulative distribution function (CDF) and its inverse are known and easy to compute, methods such as inversion sampling may be used. In practice, however, this is rarely the case. Many Monte Carlo methods, such as rejection sampling, require no knowledge of the CDF but are computationally expensive. The slice sampling algorithm is a Markov chain Monte Carlo method that generates pseudorandom numbers from a distribution by sampling uniformly from horizontal slices through the curve. Advantages of the algorithm include its simplicity, that it involves no rejections, and that it requires no external parameters to be set.
Given a starting point  , usually drawn from a uniform distribution over the abscissas, the
, usually drawn from a uniform distribution over the abscissas, the  iteration of the algorithm proceeds as follows [1]:
iteration of the algorithm proceeds as follows [1]:
1. The distribution is evaluated for  .
.
2. A random variable  is drawn from a uniform distribution over the interval
is drawn from a uniform distribution over the interval  .
.
3. Take a horizontal slice of the distribution at height . Determine the regions where the curve  lies above the slice.
lies above the slice.
4. Generate a new sample point  by drawing from a uniform distribution over the regions in step 3.
by drawing from a uniform distribution over the regions in step 3.
5. For iteration  , repeat from step 1 using as the new starting value.
, repeat from step 1 using as the new starting value.
In this Demonstration, step 3 is performed by interpolating between values in a lookup table of distribution values  . In practice, however, this method may be inaccurate, and finding exact solutions for the intersections inefficient. Modified algorithms that employ a slice width that contracts and expands exist to address these issues [1, 2].
. In practice, however, this method may be inaccurate, and finding exact solutions for the intersections inefficient. Modified algorithms that employ a slice width that contracts and expands exist to address these issues [1, 2].
[1] D. J. C. MacKay, Information Theory, Inference, and Learning Algorithms, New York: Cambridge University Press, 2003.
[2] R. M. Neal, "Slice Sampling," The Annals of Statistics, 31(3), 2003 pp. 705–767.
Permanent Citation
 Monte Carlo Sampling Coverage
Monte Carlo Sampling Coverage
Richard Roe Distributions of Order Statistics
Distributions of Order Statistics
Chris Boucher Distance Distributions in Finite Uniformly Random Point Processes
Distance Distributions in Finite Uniformly Random Point Processes
Sunil Srinivasa and Martin Haenggi The Negative Binomial Distribution
The Negative Binomial Distribution
Chris Boucher Entropy of a Message Using Random Variables
Entropy of a Message Using Random Variables
Daniel de Souza Carvalho Using Rule 30 to Generate Pseudorandom Real Numbers
Using Rule 30 to Generate Pseudorandom Real Numbers
Chris Boucher Degree Distribution on a Random Network
Degree Distribution on a Random Network
Jorge Villalobos An Increasing Preference Distribution
An Increasing Preference Distribution
Chris Boucher Distribution of Discrete Records
Distribution of Discrete Records
Heikki Ruskeepää Comparing Rule 30 Pseudorandoms to a Uniform Distribution
Comparing Rule 30 Pseudorandoms to a Uniform Distribution
Chris Boucher
-
 Pattern Formation in the Kuramoto Model
Pattern Formation in the Kuramoto Model
Oliver K. Ernst -
 Gillespie's Stochastic Simulation Algorithm for Chemical Reactions
Gillespie's Stochastic Simulation Algorithm for Chemical Reactions
Oliver K. Ernst -
 Electrodiffusion of Ions across a Neural Cell Membrane
Electrodiffusion of Ions across a Neural Cell Membrane
Oliver K. Ernst -
 Action Potential Propagation along Myelinated Axons
Action Potential Propagation along Myelinated Axons
Oliver K. Ernst -
 Picard's Method for Ordinary Differential Equations
Picard's Method for Ordinary Differential Equations
Oliver K. Ernst -
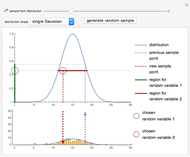 Distributions Using Slice Sampling
Distributions Using Slice Sampling
Oliver K. Ernst -
 The Hodgkin-Huxley Experiment on Neuron Conductance
The Hodgkin-Huxley Experiment on Neuron Conductance
Oliver K. Ernst -
 Tracking an Object in Space Using the Kalman Filter
Tracking an Object in Space Using the Kalman Filter
Oliver K. Ernst -
 Feedforward and Feedback Control in Neural Networks
Feedforward and Feedback Control in Neural Networks
Oliver K. Ernst