Optical Selection Rules for Zigzag Graphene Nanoribbons

Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
This Demonstration presents a complex analysis of the wavefunction parity and optical selection rules for zigzag graphene nanoribbons (ZGNRs). Selection rules are illustrated for optical transition matrix elements of a linearly polarized light. The plane of polarization of the incident light is parallel to the ribbon's longitudinal axis.
Contributed by: Vasil Saroka (August 2017)
Open content licensed under CC BY-NC-SA
Snapshots
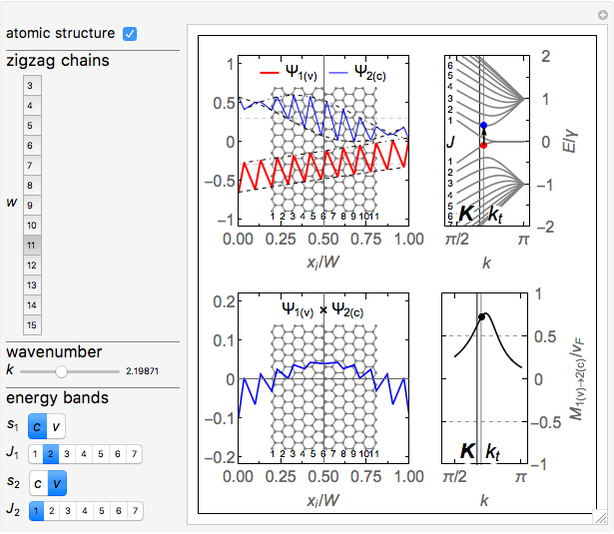

Details
This Demonstration is based on the work in [1], which is an analytical extension of the work in [2]. All the notations are adopted from there. In particular, the energy bands of the ribbon are labeled by  , where
, where  labels the band number and
labels the band number and  , the band type. Therefore,
, the band type. Therefore, 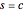 stands for the conduction band,
stands for the conduction band,  for the valence band.
for the valence band.
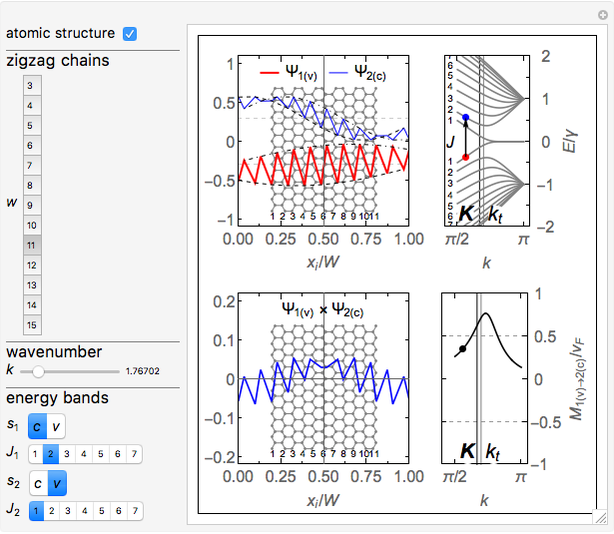
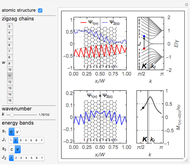
The normalized wavefunctions (blue) and
(blue) and 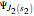 (red) are plotted in the upper-left as functions of the normalized transverse coordinate
(red) are plotted in the upper-left as functions of the normalized transverse coordinate  , where
, where  is the
is the  coordinate of the
coordinate of the  atom in the ribbon unit cell and
atom in the ribbon unit cell and 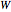 is the width of the ribbon. The coordinates of the atoms from the A and B sublattices forming a hexagonal structure of a zigzag graphene nanoribbon (ZGNR) are
is the width of the ribbon. The coordinates of the atoms from the A and B sublattices forming a hexagonal structure of a zigzag graphene nanoribbon (ZGNR) are 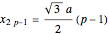 and
and 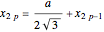 , where
, where  , with
, with 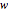 being the number of zigzag chains specifying the width of the ribbon. The number of zigzag chains is
being the number of zigzag chains specifying the width of the ribbon. The number of zigzag chains is 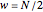 , with
, with  being the number of carbon atoms in the zigzag ribbon unit cell. Then, the ribbon width is
being the number of carbon atoms in the zigzag ribbon unit cell. Then, the ribbon width is  . Thus, the ribbon with a certain width can be labeled as
. Thus, the ribbon with a certain width can be labeled as  . The wavefunctions
. The wavefunctions  (blue) and (red) are offset for clarity by
(blue) and (red) are offset for clarity by 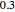 and
and  , respectively.
, respectively.
The energy bands of a chosen 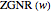 presented in the upper-right band structure plot are normalized by the hopping integral
presented in the upper-right band structure plot are normalized by the hopping integral  . The red and blue points in the band structure plot represent the states with wavefunctions and , respectively.
. The red and blue points in the band structure plot represent the states with wavefunctions and , respectively.
The lower-left plot shows the and wavefunctions overlapping for chosen 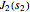 and
and 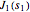 .
.
The optical matrix elements  for a chosen transition
for a chosen transition 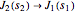 are presented in the lower right plot as functions of the electron wave number
are presented in the lower right plot as functions of the electron wave number  . These matrix elements are velocity matrix elements normalized by the Fermi velocity of electrons in graphene,
. These matrix elements are velocity matrix elements normalized by the Fermi velocity of electrons in graphene,  , where
, where  is the graphene lattice constant,
is the graphene lattice constant,  is the hopping integral, and
is the hopping integral, and  is the reduced Planck's constant. The black point denotes the matrix element value for the transition depicted in the band structure plot.
is the reduced Planck's constant. The black point denotes the matrix element value for the transition depicted in the band structure plot.
The point  corresponding to the Dirac point in graphene is marked by the vertical line labeled as
corresponding to the Dirac point in graphene is marked by the vertical line labeled as  in the energy band and matrix element plots. Similar marking by the vertical line is used for the transition point
in the energy band and matrix element plots. Similar marking by the vertical line is used for the transition point  , where the bulk states meet the edge states in the subbands
, where the bulk states meet the edge states in the subbands  and
and  .
.
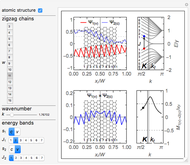
Snapshot 1: the wavefunction (red) of the bulk state in the subband of 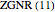
Snapshot 2: the wavefunction (red) of at the transition point 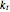 , where the bulk states meet the edge states in the subband
, where the bulk states meet the edge states in the subband
Snapshot 3: the wavefunction (red) of the subband edge states localized at the ribbon edges for
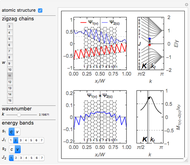
Snapshot 4: forbidden transition  between valence and conduction subbands of
between valence and conduction subbands of
Snapshot 5: allowed transition  between valence and conduction subbands of
between valence and conduction subbands of
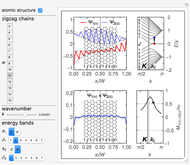
Snapshot 6: forbidden transition  between conduction subbands of
between conduction subbands of
Snapshot 7: allowed transition  between conduction subbands of
between conduction subbands of
Snapshots 1–3 show the transformation of the electron wavefunction (red) as one moves from the bulk to the edge states within the subband. Snapshots 4 and 5 demonstrate the odd selection rule  for allowed transitions between the conduction and valence subbands. Snapshots 6 and 7 demonstrate the even selection rule
for allowed transitions between the conduction and valence subbands. Snapshots 6 and 7 demonstrate the even selection rule  for allowed transitions between the conduction (valence) subbands only.
for allowed transitions between the conduction (valence) subbands only.
References
[1] V. A. Saroka, M. V. Shuba and M. E. Portnoi, "Optical Selection Rules of Zigzag Graphene Nanoribbons," Physical Review B, 95(15), 2017 155438. doi:10.1103/PhysRevB.95.155438.
[2] H. C. Chung, M. H. Lee, C. P. Chang and M. F. Lin, "Exploration of Edge-Dependent Optical Selection Rules for Graphene Nanoribbons," Optics Express, 19(23), 2011 pp. 23350–23363. doi:10.1364/OE.19.023350.
Permanent Citation
 Electronic Band Structure of Armchair and Zigzag Graphene Nanoribbons
Electronic Band Structure of Armchair and Zigzag Graphene Nanoribbons
Jessica Alfonsi Chiral Tunneling and the Klein Paradox in Graphene
Chiral Tunneling and the Klein Paradox in Graphene
Niels Walet Electronic Band Structure of a Single-Walled Carbon Nanotube by the Zone-Folding Method
Electronic Band Structure of a Single-Walled Carbon Nanotube by the Zone-Folding Method
Jessica Alfonsi (University of Padova, Italy) Models for Edge States in the Electronic Spectra of Dimer Chains
Models for Edge States in the Electronic Spectra of Dimer Chains
Jessica Alfonsi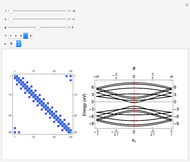 Electronic Structure of a Single-Walled Carbon Nanotube in Tight-Binding Wannier Representation
Electronic Structure of a Single-Walled Carbon Nanotube in Tight-Binding Wannier Representation
Jessica Alfonsi (University of Padova, Italy) Band Structures in Zigzag Graphene Nanoribbons and Armchair Carbon Nanotubes
Band Structures in Zigzag Graphene Nanoribbons and Armchair Carbon Nanotubes
Vasil Saroka Solving the Secular Equation for Zigzag and Bearded Graphene Nanoribbons
Solving the Secular Equation for Zigzag and Bearded Graphene Nanoribbons
Vasil Saroka Visualizing Atomic Orbitals
Visualizing Atomic Orbitals
Guenther Gsaller Electromagnetic Waves in Optical Fibers
Electromagnetic Waves in Optical Fibers
Y. Shibuya Moiré Patterns and Commensurability in Rotated Graphene Bilayers
Moiré Patterns and Commensurability in Rotated Graphene Bilayers
Jessica Alfonsi
-
 Selective Fractalization of Chevron-Type Polygons Edges
Selective Fractalization of Chevron-Type Polygons Edges
Vasil Saroka -
Band Structures in Zigzag Graphene Nanoribbons and Armchair Carbon Nanotubes
Vasil Saroka -
 Catching a Point within a Teragon
Catching a Point within a Teragon
Vasil Saroka -
Solving the Secular Equation for Zigzag and Bearded Graphene Nanoribbons
Vasil Saroka -
 Zigzag-Shaped Graphene Nanoribbons
Zigzag-Shaped Graphene Nanoribbons
Vasil Saroka -
 Optical Selection Rules for Zigzag Graphene Nanoribbons
Optical Selection Rules for Zigzag Graphene Nanoribbons
Vasil Saroka -
 Koch Curve Randomization and Crystal Edge Disorder
Koch Curve Randomization and Crystal Edge Disorder
Vasil Saroka