Recycling Robot in Reinforcement Learning

Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
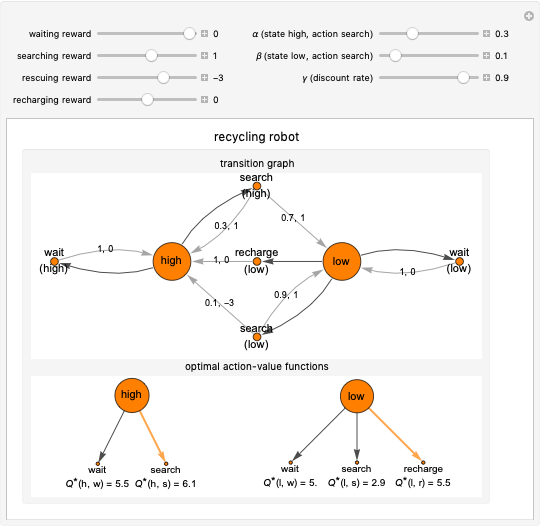
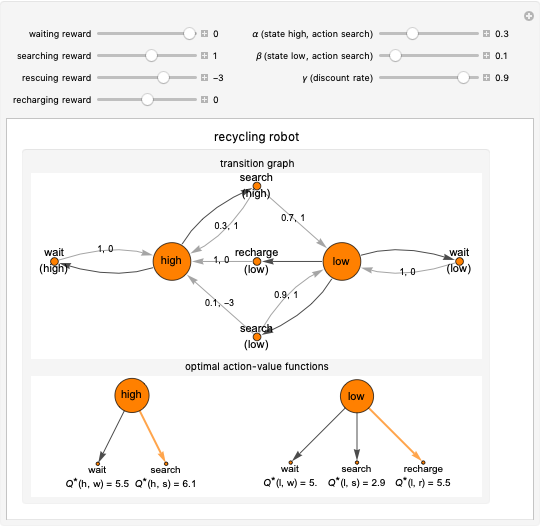
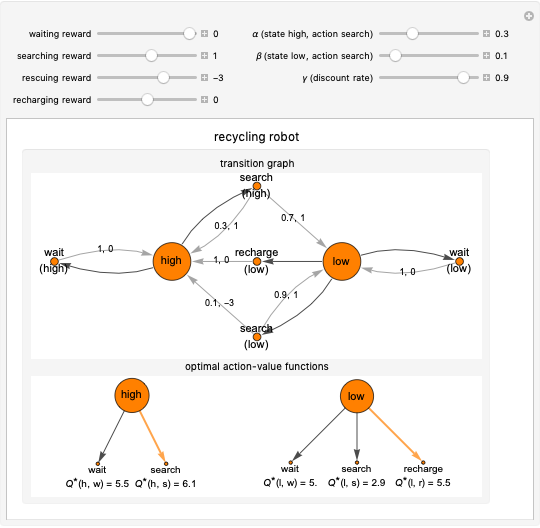
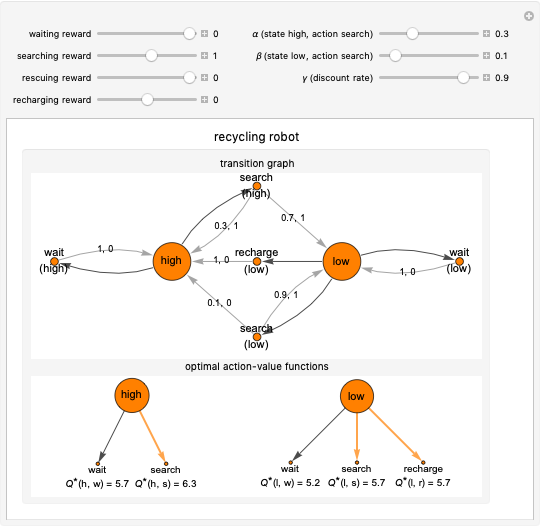
This Demonstration simulates the recycling robot task in reinforcement learning. In this scenario, a mobile robot with a rechargeable battery collects empty soda cans in an office area. In the transition graph, the state nodes represent the high and low energy levels. They are connected with black edges to two action nodes (search, wait) and to three action nodes (search, wait, recharge), respectively. On the edges of the graph, the transition probability and the reward for that transition are displayed. The separated diagrams show the action-value functions for the optimal policy, where the values are calculated based on the Bellman optimality equations. The optimal choice is highlighted in both states; in the case of multiple optimal policies in the given state, each of them is highlighted.
Contributed by: Mónika Farsang (December 2020)
Open content licensed under CC BY-NC-SA
Snapshots
Details
In the high energy level state, the two possible actions are waiting and searching. With the former, the robot waits for someone to bring it an empty can and gets the waiting reward. Choosing the latter, the robot searches for a can and gets the searching reward. During this action, the state stays the same with the probability 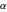 or the mobile robot loses battery power and gets to the low energy state with probability
or the mobile robot loses battery power and gets to the low energy state with probability 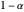 .
.
If the energy level is low, the robot has the same actions as in the high energy level state; also it can choose the recharging action, which leads to the high energy level state with the recharging reward. Whereas the waiting action in the low state does not change the position of the robot, the searching action leaves the robot in the current state with the probability 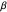 or the robot has to be rescued due to a discharged battery with probability
or the robot has to be rescued due to a discharged battery with probability 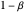 . In this case, the robot receives the rescuing reward and gets to the high energy level state.
. In this case, the robot receives the rescuing reward and gets to the high energy level state.
The Bellman optimality equation for the action-value function is given by:
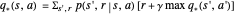 ,
,
where  is the current state,
is the current state, 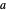 is the performed action,
is the performed action, 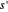 is the next state,
is the next state,  is the reward for the transition,
is the reward for the transition, 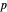 is the transition probability and
is the transition probability and 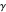 is the discount factor.
is the discount factor.
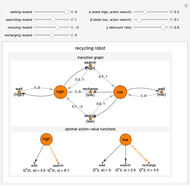
Snapshot 1: with the basic settings, the optimal action is searching in the high energy level state and it is recharging in the low energy level state
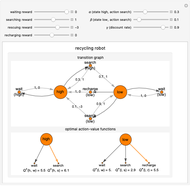
Snapshot 2: in the case of rescue, the reward is zero; there are two optimal actions in the low energy level state, which are searching and recharging
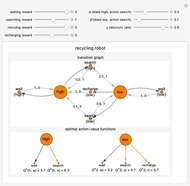
Snapshot 3: if the transition probability  is changed to 0.9, the optimal action is searching in both states
is changed to 0.9, the optimal action is searching in both states
Snapshot 4: with the condition that the searching and waiting rewards are the same, the waiting action becomes another optimal action in both states
The recycling robot exercise is described in [1].
Reference
[1] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed., Cambridge, MA: The MIT Press, 2018.
Permanent Citation
 Cluster Coloring in Machine Learning
Cluster Coloring in Machine Learning
John Hurley Perceptron Algorithm in Machine Learning
Perceptron Algorithm in Machine Learning
Arnab Kar Minimal Disjunctive Normal Form
Minimal Disjunctive Normal Form
Michael Schreiber Robot Builder
Robot Builder
Frank Liao Snake-Arm Robot
Snake-Arm Robot
Sándor Kabai Robot Manipulator Workspaces
Robot Manipulator Workspaces
Aaron T. Becker, Benedict Isichei, Muhammad Sultan and Maruthi S. Chemudupati Swerve Drive Robot
Swerve Drive Robot
Jatin Kohli Fractal Robot Arm
Fractal Robot Arm
Sándor Kabai Mobile Robot with Single Manipulator
Mobile Robot with Single Manipulator
Frederick Wu Probabilistic Models for Robot Motion
Probabilistic Models for Robot Motion
Aaron T. Becker and Renuka Pakeetharan