Delta and Perceptron Training Rules for Neuron Training

Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
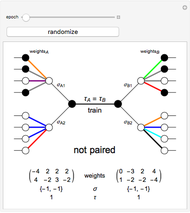
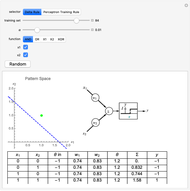
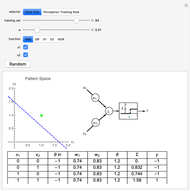
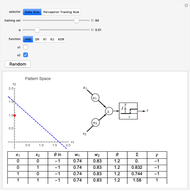
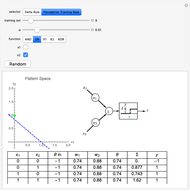
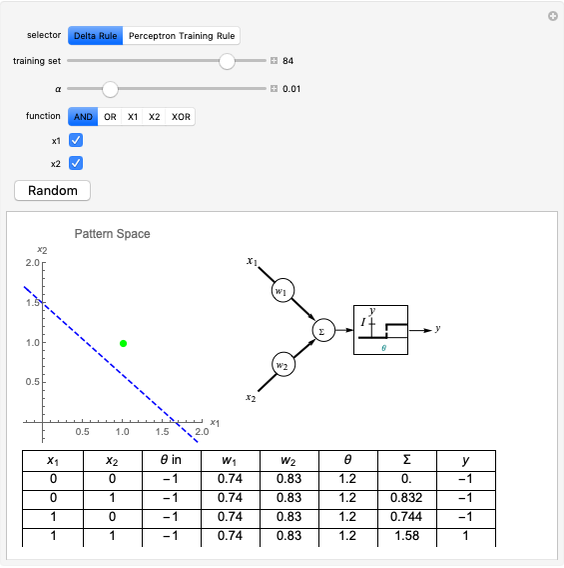
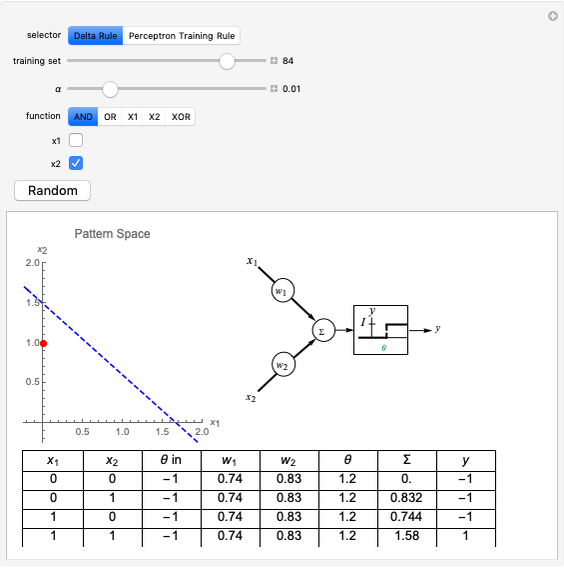
This Demonstration shows how a single neuron is trained to perform simple linear functions in the form of logic functions (AND, OR, X1, X2) and its inability to do that for a nonlinear function (XOR) using either the "delta rule" or the "perceptron training rule".
[more]
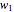
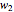
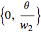
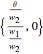
Contributed by: Hector Sanchez (July 2011)
Open content licensed under CC BY-NC-SA
Snapshots
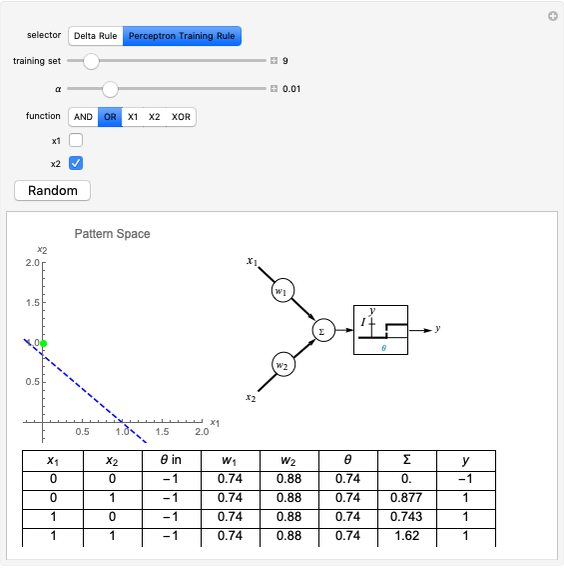
Details
Delta rule: When the neuron is trained via the delta rule, the algorithm is:
1. Evaluate the network according to the equation:  .
.
2. If the current output 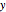 is already equal to the desired output
is already equal to the desired output  , repeat step 1 with a different set of inputs. Otherwise, proceed to step 4.
, repeat step 1 with a different set of inputs. Otherwise, proceed to step 4.
3. Adjust the current weights according to 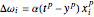 , where
, where 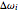 is the change in the neuron's weight,
is the change in the neuron's weight,  is the learning rate,
is the learning rate, 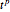 is the target output given the input set
is the target output given the input set 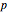 ,
, 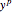 is the real output of the neuron given the input set after being passed through the threshold set by the bias
is the real output of the neuron given the input set after being passed through the threshold set by the bias  , and
, and 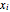 is the
is the 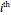 input.
input.
4. Repeat the algorithm from step 1 until  for every vector pair.
for every vector pair.
Perceptron training rule: When the perceptron training rule algorithm is selected, the steps are:
1. Evaluate the network according to the equation:  .
.
2. If the result of step 1 is greater than zero, 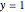 ; if it is less than zero,
; if it is less than zero,  .
.
3. If the current output is already equal to the desired output , repeat step 1 with a different set of inputs. If the current output is different from the desired output , proceed to step 4.
4. Adjust the current weights according to: 
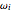

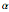
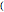

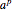
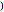
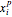 , where is the change in the neuron's weight, is the learning rate, is the target output given the input set , is the real output of the neuron given the input set without being passed through the threshold set by the bias , and is the input.
, where is the change in the neuron's weight, is the learning rate, is the target output given the input set , is the real output of the neuron given the input set without being passed through the threshold set by the bias , and is the input.
5. Repeat the algorithm from step 1 until for every vector pair.
It can be observed that the perceptron training rule gets to a finite value of weights and then stays in it, whereas the delta rule approaches certain asymptotic values but never reaches them. This is because of the origin of both rules. The perceptron training rule has a geometric value that can work directly with the value of the evaluated neuron after the threshold (logic values of 0 and 1), while the delta rule has its origin in the gradient error descent, so it works with the net value of the output without being passed through the threshold.
Reference
[1] K. Gurney, An Introduction to Neural Networks, Boca Raton, FL: CRC Press, 1997.
Permanent Citation
 Threshold Logic Unit (TLU)
Threshold Logic Unit (TLU)
Hector Sanchez Inference with Fuzzy IF-THEN Rules
Inference with Fuzzy IF-THEN Rules
Luis R. Izquierdo and Segismundo S. Izquierdo Plots of Compositions of Bitwise Operations
Plots of Compositions of Bitwise Operations
Enrique Zeleny Arithmetic in Lambda Calculus
Arithmetic in Lambda Calculus
Enrique Zeleny Recursion in the Ackermann Function
Recursion in the Ackermann Function
Stephen Wolfram Skolemization
Skolemization
Hector Zenil Truth Tables
Truth Tables
Hector Zenil Formula Generator
Formula Generator
Hector Zenil Direct Rule Control for 3,2 Turing Machines
Direct Rule Control for 3,2 Turing Machines
Michael Schreiber Direct Rule Control for 2,3 Turing Machines
Direct Rule Control for 2,3 Turing Machines
Michael Schreiber