Finite Limit at a Finite Point
Initializing live version



Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
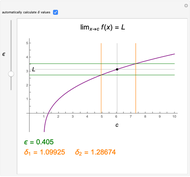
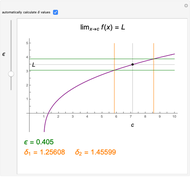
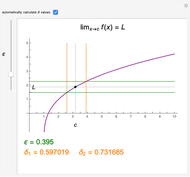
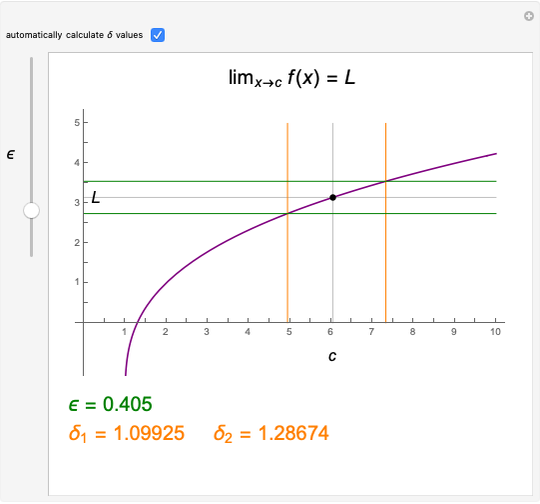
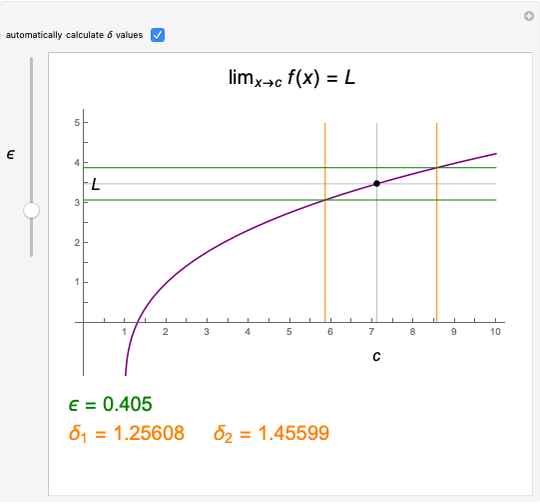
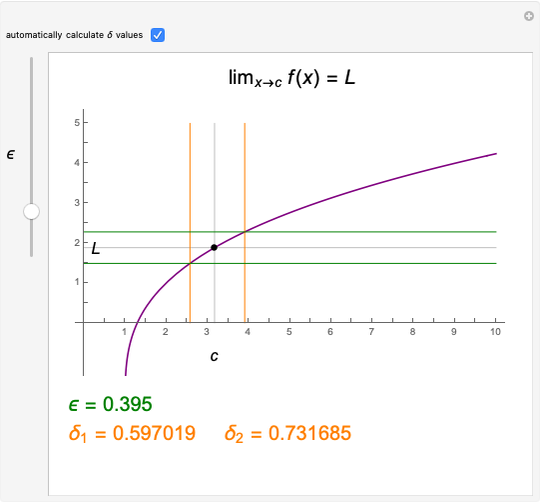
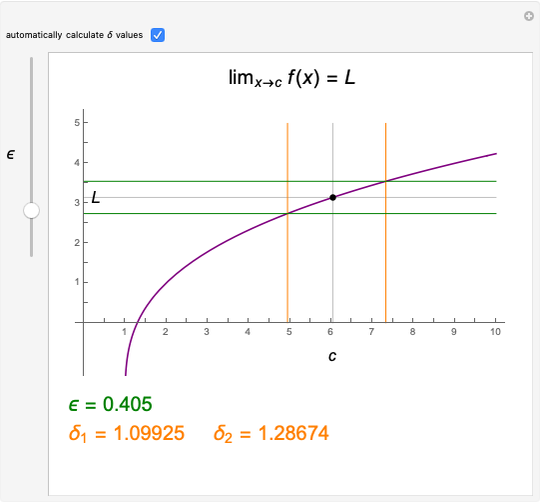
The function 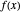 has a finite limit,
has a finite limit, 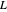 , as
, as 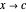 . This means that for any
. This means that for any 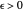 , there is an interval
, there is an interval 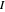 of width
of width 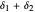 around
around  (perhaps with
(perhaps with 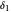 and
and 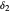 very small), such that
very small), such that 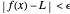 whenever
whenever 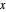 is in the interval
is in the interval 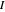 . Move the point directly and vary
. Move the point directly and vary  using the slider. This Demonstration computes the largest
using the slider. This Demonstration computes the largest 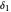 and
and 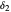 for a given
for a given  so that
so that 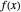 lies between
lies between 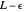 and
and 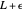 . The values for
. The values for 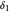 and
and 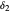 may be found automatically or manually by dragging. The function shown is
may be found automatically or manually by dragging. The function shown is 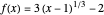 .
.
Contributed by: Abby Brown (March 2011)
Open content licensed under CC BY-NC-SA
Snapshots
Details
Permanent Citation
Related Demonstrations
More by Author
 Infinite Limit at a Finite Point
Infinite Limit at a Finite Point
Abby Brown Finite Limit at Infinity
Finite Limit at Infinity
Abby Brown Infinite Limit at Infinity
Infinite Limit at Infinity
Abby Brown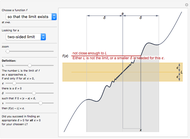 Epsilon-Delta Definition of Limit
Epsilon-Delta Definition of Limit
Ferenc Beleznay Limit of the Sequence a^(1/n)
Limit of the Sequence a^(1/n)
Izidor Hafner Examples of Asymptotes in 2D and 3D
Examples of Asymptotes in 2D and 3D
Abby Brown Circular Asymptote
Circular Asymptote
Abby Brown Spherical Asymptote
Spherical Asymptote
Abby Brown Toroidal Asymptote
Toroidal Asymptote
Abby Brown Cylindrical Asymptote
Cylindrical Asymptote
Abby Brown
-
 Finite Limit at a Finite Point
Finite Limit at a Finite Point
Abby Brown -
 Adding to Color Channels
Adding to Color Channels
Abby Brown -
 Parametric Equations for a Hyperbola
Parametric Equations for a Hyperbola
Abby Brown -
 Series: Steps on a Number Line
Series: Steps on a Number Line
Abby Brown -
 Snowflake Designs
Snowflake Designs
Abby Brown -
 Morphing Cartesian to Polar Coordinates
Morphing Cartesian to Polar Coordinates
Abby Brown -
 Derivative of a Vector-Valued Function in 2D
Derivative of a Vector-Valued Function in 2D
Abby Brown -
 Spinning Action
Spinning Action
Abby Brown -
 Fireworks with Regular Polygon and Circle Points
Fireworks with Regular Polygon and Circle Points
Abby Brown -
 3D Zoetrope
3D Zoetrope
Abby Brown -
 Color Gradient Sliders
Color Gradient Sliders
Abby Brown -
 Logistic Model for Population Growth
Logistic Model for Population Growth
Abby Brown -
 Exponential Model for Population Growth
Exponential Model for Population Growth
Abby Brown -
 The Phosphorus Cycle
The Phosphorus Cycle
Abby Brown -
 Approximating Polar Area with Sectors
Approximating Polar Area with Sectors
Abby Brown -
 Let's Learn French! An Interactive Learning Game
Let's Learn French! An Interactive Learning Game
Abby Brown -
 Animal Cell Structure
Animal Cell Structure
Abby Brown -
 The Nitrogen Cycle
The Nitrogen Cycle
Abby Brown -
 The Carbon Cycle
The Carbon Cycle
Abby Brown -
 Lines: Two Points
Lines: Two Points
Abby Brown