Huffman Tree Encoding

Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
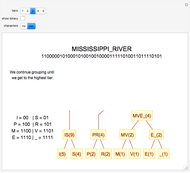
The basic idea of Huffman encoding is that more frequent characters are represented by fewer bits. With the ASCII system, each character is represented by eight bits (one byte). But with the Huffman tree, the most-often-repeated characters require fewer bits. For example, if I wanted to send "Mississippi_River" in ASCII, it would take 136 bits (17 characters × 8 bits). If I wanted to send that same message using Huffman coding, it would take 46 bits, which is 66% more efficient. Using this example, this Demonstration gives a step-by-step analysis to get to the binary output.
Contributed by: Piril Nergis (February 2017)
Open content licensed under CC BY-NC-SA
Snapshots
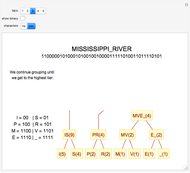
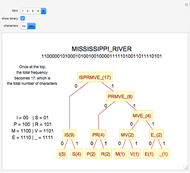
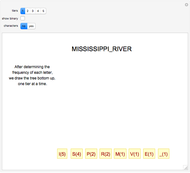
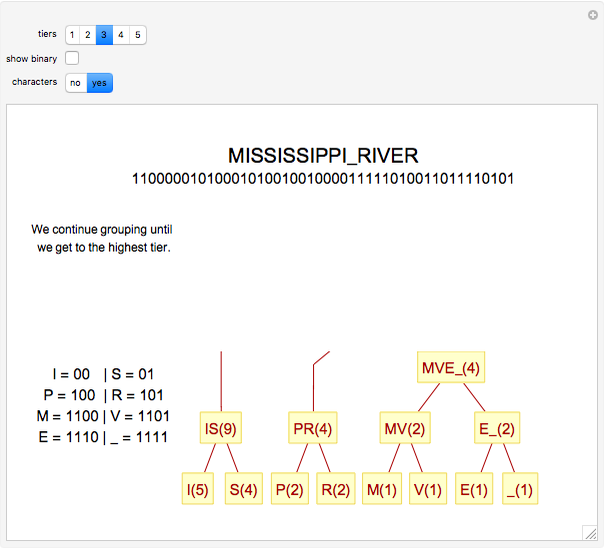
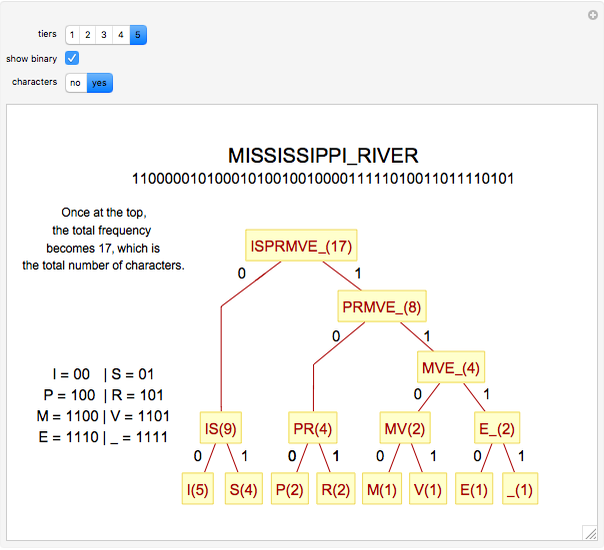
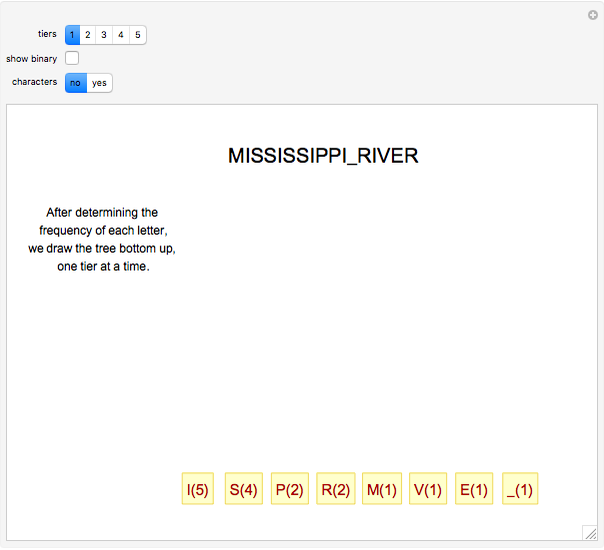
Details
Huffman coding is a data representation system used for lossless data compression. It significantly decreases the total number of bits used. David A. Huffman, while an ScD student at MIT, created this algorithm in order to get out of his final exam.
This was a project for Advanced Topics in Mathematics II, fall 2016, Torrey Pines High School, San Diego, CA.
Permanent Citation
"Huffman Tree Encoding"
http://demonstrations.wolfram.com/HuffmanTreeEncoding/
Wolfram Demonstrations Project
Published: February 6 2017
 Greedy Algorithms for a Minimum Spanning Tree
Greedy Algorithms for a Minimum Spanning Tree
Frederick Wu The Geometry of the Steiner Tree Problem for up to Five Points
The Geometry of the Steiner Tree Problem for up to Five Points
Ferenc Beleznay Optimal Bin Packing with Random Lengths
Optimal Bin Packing with Random Lengths
Yifan Hu and Stephen Wolfram Comparing Sorting Algorithms on Rainbow-Colored Bar Charts
Comparing Sorting Algorithms on Rainbow-Colored Bar Charts
Michael Zhou and Karolina Urban Oriented Run-Length Compression
Oriented Run-Length Compression
Michael Schreiber Self-Delimiting Binary Representation of a Ternary List
Self-Delimiting Binary Representation of a Ternary List
Michael Schreiber Quantum Circuit Implementing Grover's Search Algorithm
Quantum Circuit Implementing Grover's Search Algorithm
Alexander Prokopenya Grover's Quantum Search Algorithm
Grover's Quantum Search Algorithm
Tad Hogg Quantum Computer Search Algorithms
Quantum Computer Search Algorithms
Tad Hogg The Traveling Salesman Problem 4: Spanning Tree Heuristic
The Traveling Salesman Problem 4: Spanning Tree Heuristic
Jaime Rangel-Mondragon