Merging Mountains




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
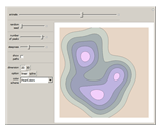
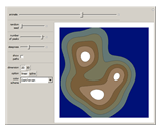
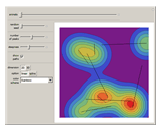
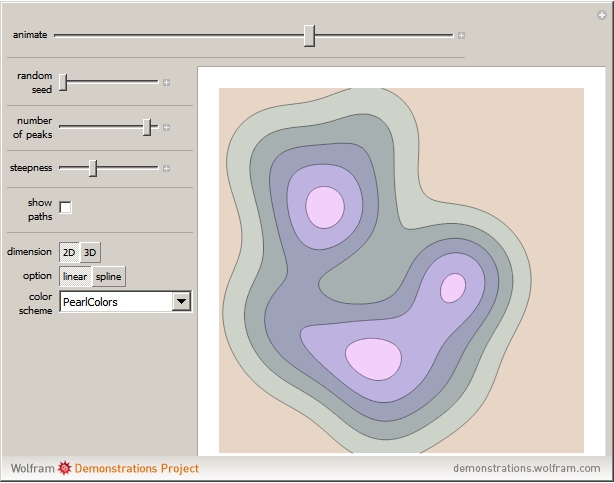
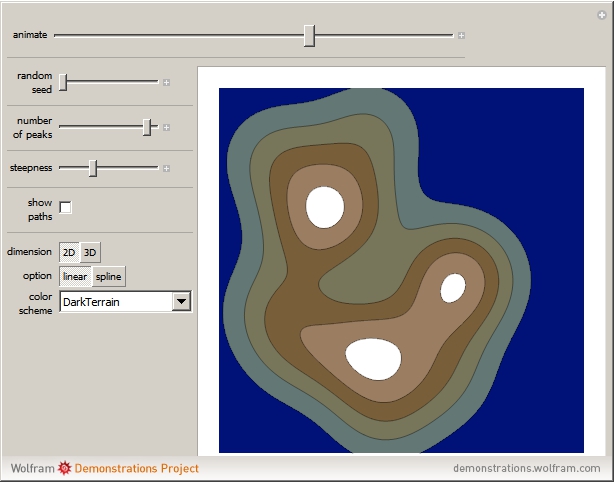
A set of points is selected parametrically from either a set of randomly generated line segments or from a randomly generated set of closed B-spline paths. Each point is the tip of a three-dimensional Gaussian curve that appears as a mountain. The mountains merge together and separate as the points follow their paths. You can view the mountains either as a 3D plot or as a 2D contour map. When viewed as a contour map, you can show the paths superimposed over it. You can modify the steepness of the mountains in relation to the diameter of its base with the "steepness" slider. Setting the top slider to play gives interesting animations.
Contributed by: Noel Patson (September 2013)
Open content licensed under CC BY-NC-SA
Snapshots
Details
detailSectionParagraphPermanent Citation
"Merging Mountains"
http://demonstrations.wolfram.com/MergingMountains/
Wolfram Demonstrations Project
Published: September 9 2013
 The Shortest Distance to a Trefoil Knot
The Shortest Distance to a Trefoil Knot
Machi Zawidzki An Enneper-Weierstrass Minimal Surface
An Enneper-Weierstrass Minimal Surface
Michael Schreiber Exploring Cylindrical Coordinates
Exploring Cylindrical Coordinates
Faisal Mohamed Gauss Map and Curvature
Gauss Map and Curvature
Michael Rogers (Oxford College/Emory University) Real Elliptic Curves
Real Elliptic Curves
Zubeyir Cinkir 3D Object Designer Using Splines
3D Object Designer Using Splines
Erik Mahieu Sinusoidal Bellows
Sinusoidal Bellows
Sándor Kabai Potter's Wheel
Potter's Wheel
Yu-Sung Chang Curves of Steepest Descent for 3D Functions
Curves of Steepest Descent for 3D Functions
Michael Waters Constructing a Swung Surface around a B-Spline Curve
Constructing a Swung Surface around a B-Spline Curve
Shutao Tang
-
 Merging Mountains
Merging Mountains
Noel Patson -
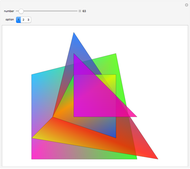 Lagrange's Four-Square Theorem Seen Using Polygons and Lines
Lagrange's Four-Square Theorem Seen Using Polygons and Lines
Noel Patson -
 Ways of Stepping One, Two, or Three Stairs Up a Stairway
Ways of Stepping One, Two, or Three Stairs Up a Stairway
Noel Patson -
 Clock Hand Tips
Clock Hand Tips
Noel Patson -
 Real Digits Carpet
Real Digits Carpet
Noel Patson -
 Line Art 3
Line Art 3
Noel Patson -
 Overlapping Patterns
Overlapping Patterns
Noel Patson -
 Abstract Art
Abstract Art
Noel Patson -
 Equal Incircles along a Line
Equal Incircles along a Line
Noel Patson -
 Three Touching Circles on a Line
Three Touching Circles on a Line
Noel Patson -
 Prime Walk
Prime Walk
Noel Patson -
 Irrational Digits Walk
Irrational Digits Walk
Noel Patson -
 Generalized Digit Parity for Integer Sequences
Generalized Digit Parity for Integer Sequences
Noel Patson -
 Möbius Mu Function Walk
Möbius Mu Function Walk
Noel Patson -
 Number of Repeating Digits in Base b Expansion of Fractions
Number of Repeating Digits in Base b Expansion of Fractions
Noel Patson -
 Generalized Kaprekar Routine
Generalized Kaprekar Routine
Noel Patson -
 Generalized Digit Parity
Generalized Digit Parity
Noel Patson -
 Oscillations of a Pogo Stick
Oscillations of a Pogo Stick
Noel Patson -
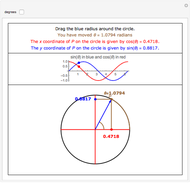 Relationship of Sine and Cosine to the Unit Circle
Relationship of Sine and Cosine to the Unit Circle
Noel Patson -
 Square Matrix Permutations
Square Matrix Permutations
Noel Patson