Solve the Cryptoquote


Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
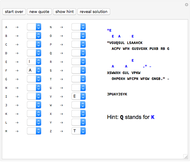
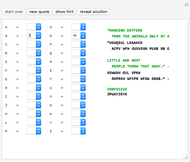
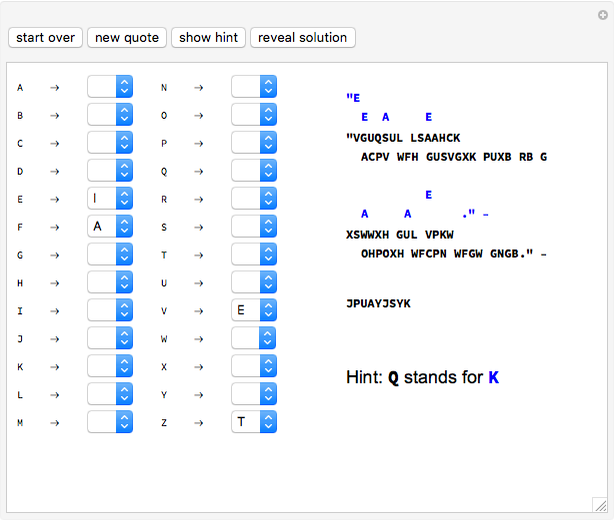
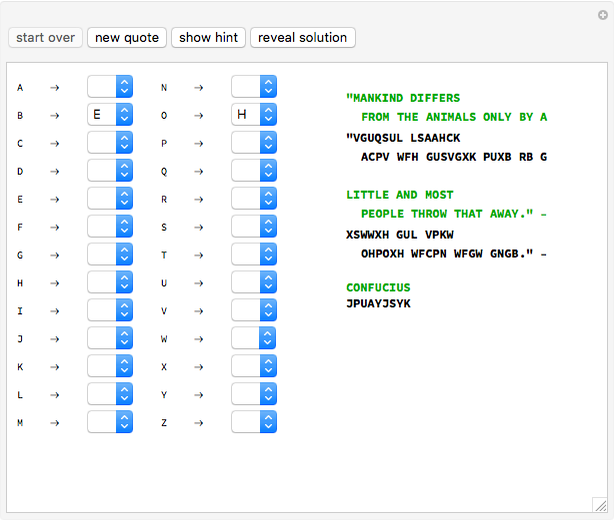
Try your hand at decoding some famous quotes encoded using a substitution cipher. The person to whom the quote is attributed is encoded after the quote. Each cipher is a derangement of the letters of the alphabet, so that no letter stands for itself. If you need a hint to get started, the "show hint" button will randomly select a letter in the coded message and decode it for you.
Contributed by: Marc Brodie (Wheeling Jesuit University) (April 2011)
Open content licensed under CC BY-NC-SA
Snapshots

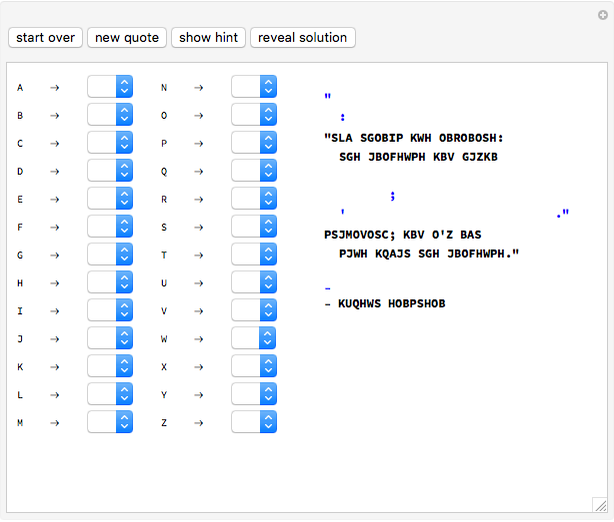
Details
At any time you can change your guess for what a given letter represents. You can remove your guess for a given letter by using the pull-down menu and selecting the blank at that letter's place in the alphabet. If you want to clear all your work and try decoding the message again from scratch, use the "start over" button. There are 54 quotes included, one of which will be selected at random when you click the "new quote" button. Asking for a new quote will automatically generate a new code, so your work from decoding a previous message will not be of direct use.
Permanent Citation
 The Vigenère Cipher
The Vigenère Cipher
Marc Brodie The Decimation Cipher
The Decimation Cipher
Marc Brodie Solve the Cryptoquote Automatically
Solve the Cryptoquote Automatically
Andy Ross Cipher Encoder
Cipher Encoder
Jon McLoone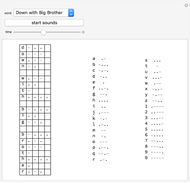 Morse Code Emitter
Morse Code Emitter
Hector Sanchez Encryption with the Enigma Machine
Encryption with the Enigma Machine
Gasper Zadnik Learn the Radio Code
Learn the Radio Code
Anthony I. Joseph Hashing Words in Cryptography
Hashing Words in Cryptography
Daniel de Souza Carvalho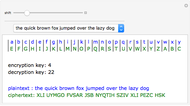 Additive Cipher
Additive Cipher
Shawna Martell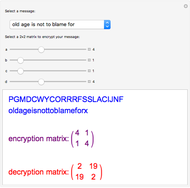 Hill Cipher Encryption and Decryption
Hill Cipher Encryption and Decryption
Greg Wilhelm
-
 Arranging Balls into Boxes
Arranging Balls into Boxes
Marc Brodie -
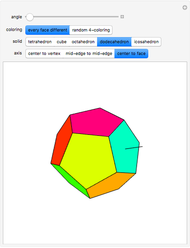 Rotational Symmetries of Colored Platonic Solids
Rotational Symmetries of Colored Platonic Solids
Marc Brodie -
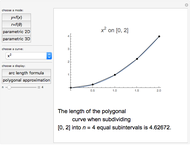 Arc Length and Polygonal Approximations
Arc Length and Polygonal Approximations
Marc Brodie -
 Subgroup Lattices of Finite Cyclic Groups
Subgroup Lattices of Finite Cyclic Groups
Marc Brodie -
 Venn Diagrams and Syllogisms
Venn Diagrams and Syllogisms
Marc Brodie -
 Crossword Grid Maker
Crossword Grid Maker
Marc Brodie -
 UPC Bar Code
UPC Bar Code
Marc Brodie -
 Recognizing Notes in the Context of a Key
Recognizing Notes in the Context of a Key
Marc Brodie -
 Locus of Points Definition of an Ellipse, Hyperbola, Parabola, and Oval of Cassini
Locus of Points Definition of an Ellipse, Hyperbola, Parabola, and Oval of Cassini
Marc Brodie -
 The Music of Mathematical Constants
The Music of Mathematical Constants
Marc Brodie -
 Exploring Relations on Sets
Exploring Relations on Sets
Marc Brodie -
 Subgroup Lattices of Groups of Small Order
Subgroup Lattices of Groups of Small Order
Marc Brodie -
 Math Trivia Game
Math Trivia Game
Marc Brodie -
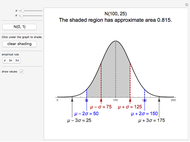 The Empirical Rule for Normal Distributions
The Empirical Rule for Normal Distributions
Marc Brodie -
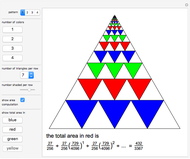 Geometric Series Based on Equilateral Triangles
Geometric Series Based on Equilateral Triangles
Marc Brodie -
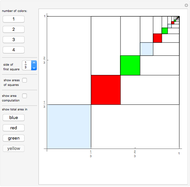 Geometric Series Based on the Areas of Squares
Geometric Series Based on the Areas of Squares
Marc Brodie -
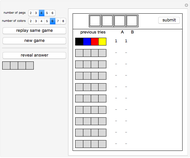 Bulls and Cows
Bulls and Cows
Marc Brodie -
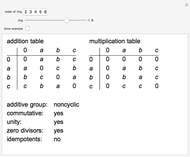 Rings of Small Order
Rings of Small Order
Marc Brodie -
 Counting Necklaces
Counting Necklaces
Marc Brodie -
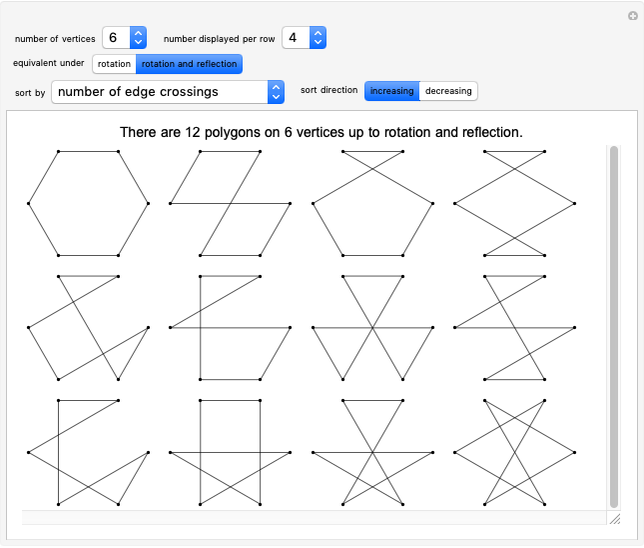 Polygons on n Vertices
Polygons on n Vertices
Marc Brodie