Coupler Curves of a Four-Bar Linkage




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
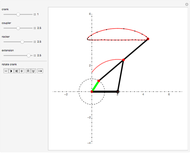
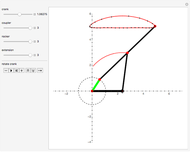
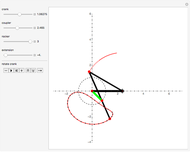
This Demonstration simulates a planar four-bar linkage mechanism and computes the path traced by a point on its coupler bar.
[more]
Contributed by: Erik Mahieu (November 2012)
Open content licensed under CC BY-NC-SA
Snapshots



Details
Grashof's law [1] states that the sum of the longest and the shortest link must be less than or equal to the sum of the remaining two links. This condition must be met to allow at least one link to make a complete revolution.
The four-bar linkage of this Demonstration has four joints ( ) and a total of four links (
) and a total of four links ( ), of which one is grounded (
), of which one is grounded ( ). According to Gruebler's equation for planar mechanisms [2], the number of degrees of freedom is
). According to Gruebler's equation for planar mechanisms [2], the number of degrees of freedom is  .
.
The Freudenstein equation [3] is used to compute the kinematics of a four-bar linkage.
The Hoekens linkage [4] generates an almost rectilinear coupler curve. The Chebyshev lambda mechanism is very similar. See the bookmarks, snapshots 1 and 2, and the Demonstration "Chebishevs Lambda Mechanism" by Nikita Panyunin.
References
[1] "Grashof's Law." eNotes: Mechanical Engineering. engineeronadisk.com/notes_mechanic/mechanismsa6.html.
[2] A. Tchako. "Degree of Freedom." Union College Mechanical Engineering (MER 312: Dynamics and Kinematics (of Mechanisms)). (2008) www.engineering.union.edu/~tchakoa/mer312/Lectures/Lecture%202.pdf.
[3] A. Ghosal, "The Freudenstein Equation: Design of Four-Link Mechanisms," Resonance, 15(8), 2010 pp. 699–710.
[4] Wikipedia. "Hoekens Linkage." (Sept 7, 2012) en.wikipedia.org/wiki/Hoekens_linkage.
Permanent Citation
"Coupler Curves of a Four-Bar Linkage"
http://demonstrations.wolfram.com/CouplerCurvesOfAFourBarLinkage/
Wolfram Demonstrations Project
Published: November 5 2012
 Five-Bar Linkage Model of the Bicycle-Rider System
Five-Bar Linkage Model of the Bicycle-Rider System
Erik Mahieu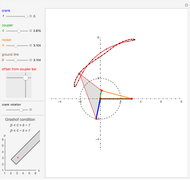 Coupler Curve Atlas for the Four-Bar Linkage
Coupler Curve Atlas for the Four-Bar Linkage
Erik Mahieu Designs from Mechanical Linkages
Designs from Mechanical Linkages
Erik Mahieu Watt's Lemniscoidal Linkage
Watt's Lemniscoidal Linkage
Erik Mahieu Walking Mechanism Using a Klann Linkage
Walking Mechanism Using a Klann Linkage
Erik Mahieu Configuration Space for Four-Bar Linkage
Configuration Space for Four-Bar Linkage
Aaron T. Becker and Shiva Shahrokhi Piston Linkage
Piston Linkage
Michael Schreiber Approximating Ackermann Steering Geometry with a Trapezoidal Linkage
Approximating Ackermann Steering Geometry with a Trapezoidal Linkage
David Askins-Gast Rolling Cycloidal Curves
Rolling Cycloidal Curves
Erik Mahieu Crane Model
Crane Model
Sándor Kabai
-
 4. Ambiguous Rings Based on a Heart Curve
4. Ambiguous Rings Based on a Heart Curve
Erik Mahieu -
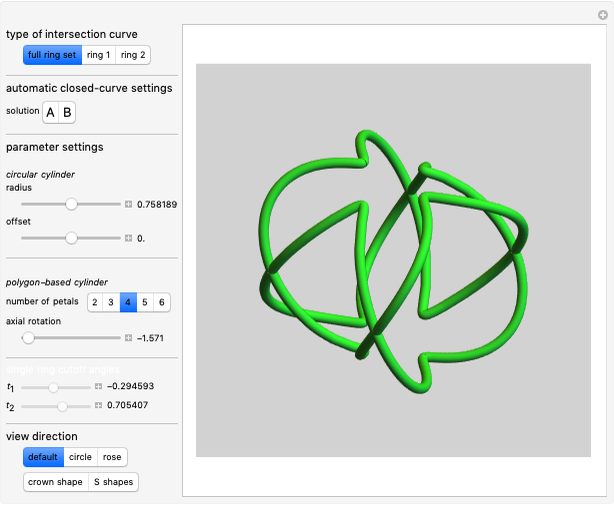 3. Ambiguous Rings Based on a Rose Curve
3. Ambiguous Rings Based on a Rose Curve
Erik Mahieu -
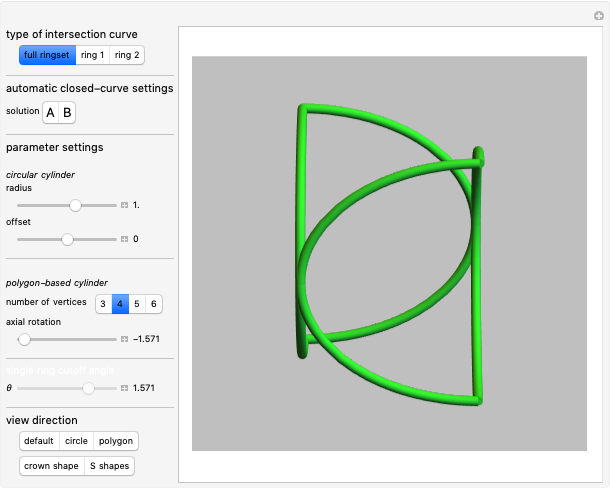 2. Ambiguous Rings Based on a Polygon
2. Ambiguous Rings Based on a Polygon
Erik Mahieu -
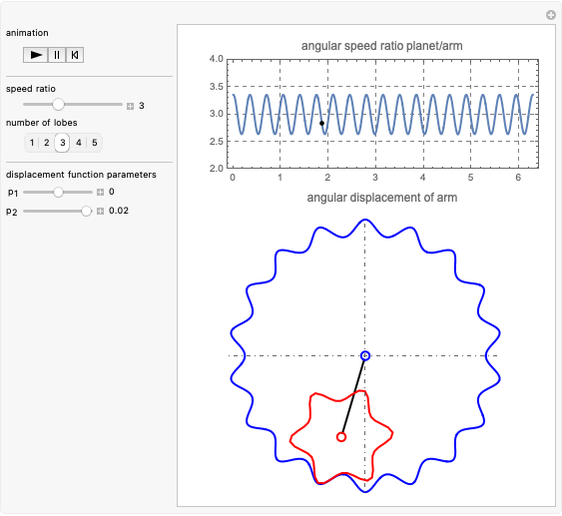 Noncircular Planetary Drive
Noncircular Planetary Drive
Erik Mahieu -
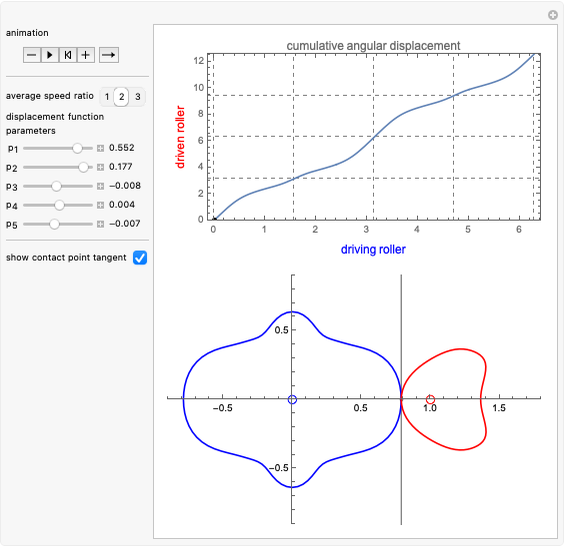 Noncircular Roller Drive
Noncircular Roller Drive
Erik Mahieu -
 Planetary Gear Train
Planetary Gear Train
Erik Mahieu -
Rolling Cycloidal Curves
Erik Mahieu -
 Driven Spherical Pendulum
Driven Spherical Pendulum
Erik Mahieu -
 Automatic Feedback Control of a Pendulum-and-Cart System
Automatic Feedback Control of a Pendulum-and-Cart System
Erik Mahieu -
 Intersection of a Generalized Cylinder over a Rose Curve with a Circular Cylinder
Intersection of a Generalized Cylinder over a Rose Curve with a Circular Cylinder
Erik Mahieu -
 1. Ambiguous Rings
1. Ambiguous Rings
Erik Mahieu -
 Elliptic Epitrochoid
Elliptic Epitrochoid
Erik Mahieu -
 Intersection of Two Polygonal Cylinders
Intersection of Two Polygonal Cylinders
Erik Mahieu -
Designs from Mechanical Linkages
Erik Mahieu -
 3D Extrusion Using the Frenet-Serret System
3D Extrusion Using the Frenet-Serret System
Erik Mahieu -
 Daylight Calculator
Daylight Calculator
Erik Mahieu -
 Astronomical Clock
Astronomical Clock
Erik Mahieu -
 Cylindrical Anamorphosis of 3D Polygonal Meshes
Cylindrical Anamorphosis of 3D Polygonal Meshes
Erik Mahieu -
 Cylindrical Anamorphosis of Parametric Surfaces
Cylindrical Anamorphosis of Parametric Surfaces
Erik Mahieu -
 Roulette (Hypotrochogon) of a Polygon Rolling inside a Circle
Roulette (Hypotrochogon) of a Polygon Rolling inside a Circle
Erik Mahieu