Cubic Twist
Initializing live version




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
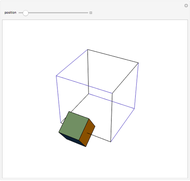
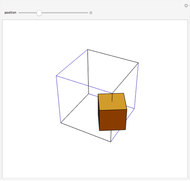
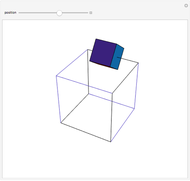
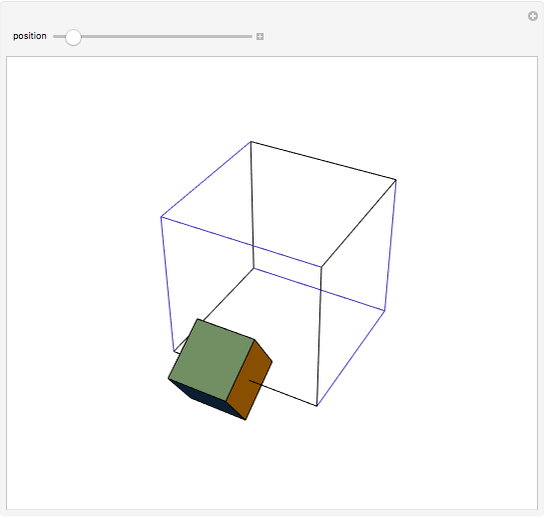
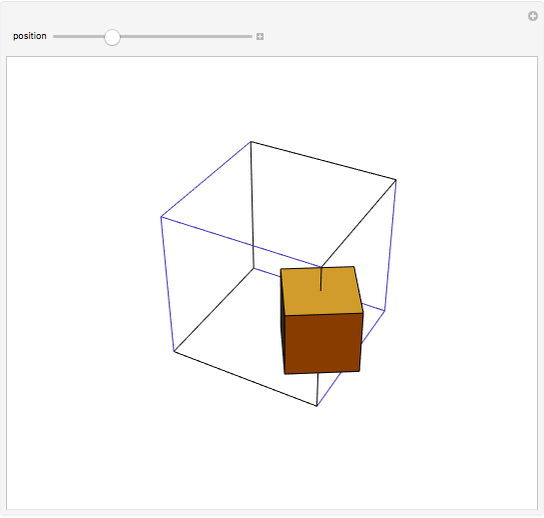
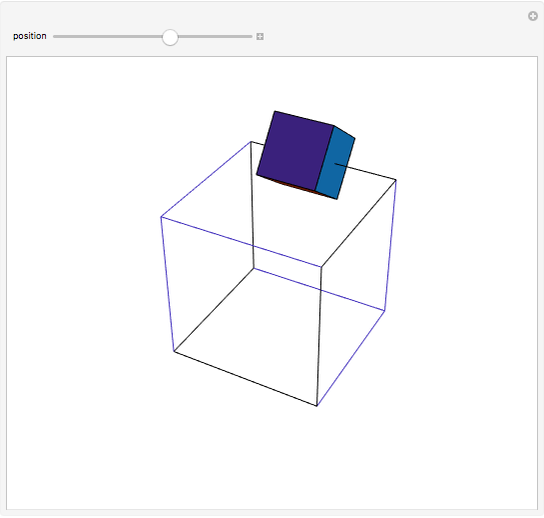
A cube travels along six of the edges of a larger skeleton cube. On each edge it rotates a quarter turn. It returns to its original position as if unturned.
Contributed by: George Beck (March 2011)
Open content licensed under CC BY-NC-SA
Snapshots
Details
detailSectionParagraphPermanent Citation
"Cubic Twist"
http://demonstrations.wolfram.com/CubicTwist/
Wolfram Demonstrations Project
Published: March 7 2011
Related Demonstrations
More by Author
 Cubic Symmetry Types
Cubic Symmetry Types
Izidor Hafner Rubik's Cube Mechanism
Rubik's Cube Mechanism
Erik Mahieu Twisted Polygonal Torus
Twisted Polygonal Torus
V. M. Chapela and M. J. Percino Rectangles Reasonably Close to a Given Area
Rectangles Reasonably Close to a Given Area
Ed Pegg Jr Polyhedra Perspective Problems
Polyhedra Perspective Problems
Izidor Hafner Four Interwoven Triangles
Four Interwoven Triangles
Sándor Kabai Rubik's Snake Puzzle
Rubik's Snake Puzzle
Frederick Wu Mazes on Polyhedra
Mazes on Polyhedra
Izidor Hafner Twist-Hinged Dissection of Squares
Twist-Hinged Dissection of Squares
Izidor Hafner A Twist-Hinged Dissection of Triangles
A Twist-Hinged Dissection of Triangles
Izidor Hafner
-
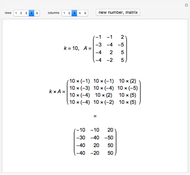 Multiplying a Matrix by a Number
Multiplying a Matrix by a Number
George Beck -
 Matrix Addition and Subtraction
Matrix Addition and Subtraction
George Beck -
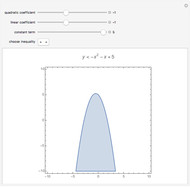 Plot a Quadratic Inequality
Plot a Quadratic Inequality
George Beck -
 Insphere and Four Exspheres of a Tetrahedron
Insphere and Four Exspheres of a Tetrahedron
George Beck -
 Permutations, k-Permutations and Combinations
Permutations, k-Permutations and Combinations
George Beck -
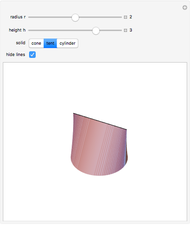 Cone, Tent, and Cylinder
Cone, Tent, and Cylinder
George Beck -
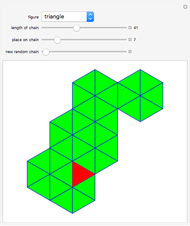 Chains of Regular Polygons and Polyhedra
Chains of Regular Polygons and Polyhedra
George Beck -
 Rotational Symmetries of Platonic Solids
Rotational Symmetries of Platonic Solids
George Beck -
 Rotational Symmetries of Colored Platonic Solids
Rotational Symmetries of Colored Platonic Solids
George Beck -
 Duals by Rotating the Edges of Polyhedra
Duals by Rotating the Edges of Polyhedra
George Beck -
 Combining Two 3D Rotations
Combining Two 3D Rotations
George Beck -
 Passing a Cube through a Cube of the Same Size
Passing a Cube through a Cube of the Same Size
George Beck -
 0/1-Polytopes in 3D
0/1-Polytopes in 3D
George Beck -
 The Path of a Ray on a Cube
The Path of a Ray on a Cube
George Beck -
 Applications of Lanchester's Square Law
Applications of Lanchester's Square Law
George Beck -
 Eulerian Numbers versus Stirling Numbers of the First Kind
Eulerian Numbers versus Stirling Numbers of the First Kind
George Beck -
 Multiple Reflections of a Regular Polygon in Its Sides
Multiple Reflections of a Regular Polygon in Its Sides
George Beck -
 The Four-Runner Problem
The Four-Runner Problem
George Beck -
 Iteratively Reflecting a Point in the Sides of a Triangle
Iteratively Reflecting a Point in the Sides of a Triangle
George Beck -
 Wythoff's Icosahedral Kaleidoscope
Wythoff's Icosahedral Kaleidoscope
George Beck