Collocation by Chi Square




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
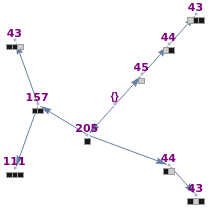
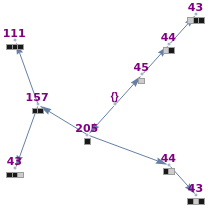
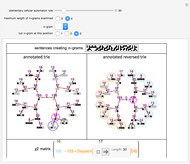
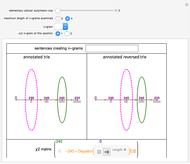
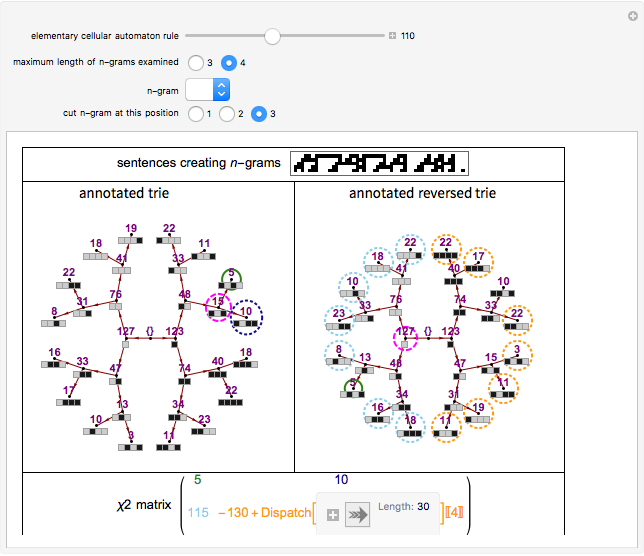
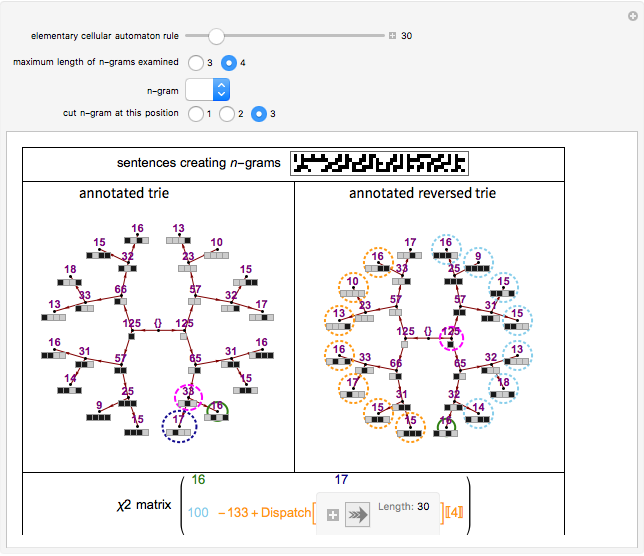
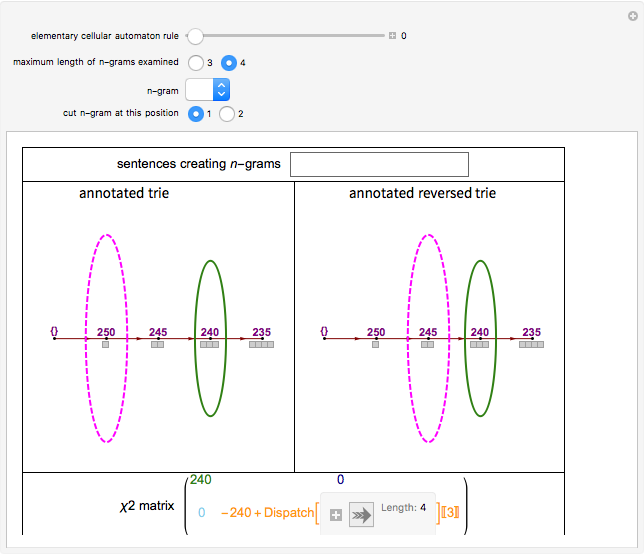
Roughly speaking, a "collocation" is an  -gram (subsequence) that appears more frequently in some sequence than would be expected if the constituent parts of the -gram were drawn at random. One way of making this definition more precise is to create a
-gram (subsequence) that appears more frequently in some sequence than would be expected if the constituent parts of the -gram were drawn at random. One way of making this definition more precise is to create a 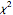 matrix. This Demonstration shows how this concept can be built into an algorithm when the sequence is stored as a "trie", that is, a data structure that converts "sentences" of symbols into a tree structure by requiring that all -grams up to a certain length that appear in a sentence have as their parent "most" of that -gram, that is, all but the rightmost element of the original -gram.
matrix. This Demonstration shows how this concept can be built into an algorithm when the sequence is stored as a "trie", that is, a data structure that converts "sentences" of symbols into a tree structure by requiring that all -grams up to a certain length that appear in a sentence have as their parent "most" of that -gram, that is, all but the rightmost element of the original -gram.
Contributed by: Seth J. Chandler (June 2008)
Open content licensed under CC BY-NC-SA
Snapshots
Details
The matrix of a bigram with parts  and
and 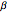 is
is
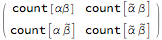
where count represents the number of times an -gram appears in the sequence and  represents any -gram except
represents any -gram except  . Thus,
. Thus, 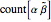 represents any length-two -gram the first part of which is but the second part of which is not . One can then calculate the value for this matrix and the probability (
represents any length-two -gram the first part of which is but the second part of which is not . One can then calculate the value for this matrix and the probability (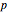 -statistic) that the first and second parts of the bigram would appear together as frequently as they do by chance. This concept can be extended to -grams by cutting the -gram at all positions
-statistic) that the first and second parts of the bigram would appear together as frequently as they do by chance. This concept can be extended to -grams by cutting the -gram at all positions 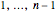 (where is the length of the -gram), finding the matrix for this "pseudo-bigram", and then taking the mean or maximum of the results.
(where is the length of the -gram), finding the matrix for this "pseudo-bigram", and then taking the mean or maximum of the results.
A discussion of this methodology may be found at:
J. F. da Silva and G. P. Lopes, "A Local Maxima Method and Fair Dispersion Normalization for Extracting Multi-Word Units from Corpora," in Proceedings of the 6th Meeting on Mathematics of Language, pp. 369–381, Orlando, July 1999.
Permanent Citation
 Collocation by Symmetric Conditional Probability
Collocation by Symmetric Conditional Probability
Seth J. Chandler Tries
Tries
Seth J. Chandler Elementary Cellular Automaton Rules by Gray Code
Elementary Cellular Automaton Rules by Gray Code
Michael Schreiber Communities of Nations Bridged by Language Similarity
Communities of Nations Bridged by Language Similarity
Seth J. Chandler Shakespearean Networks
Shakespearean Networks
Seth J. Chandler k-Cayley Trees
k-Cayley Trees
Filip Piekniewski Fibonacci Tree
Fibonacci Tree
Sándor Kabai The Tree of All Fractions
The Tree of All Fractions
Keith Schneider Regular k-ary Trees
Regular k-ary Trees
Stephen Wolfram Tree Branching in 4D
Tree Branching in 4D
Todd Rowland
-
 Post-Event Bonding
Post-Event Bonding
Seth J. Chandler -
 Emulating Land Use Evolution with a Cellular Automaton
Emulating Land Use Evolution with a Cellular Automaton
Seth J. Chandler -
 General Assembly Resolution Viewer
General Assembly Resolution Viewer
Seth J. Chandler -
 Random Acyclic Networks
Random Acyclic Networks
Seth J. Chandler -
 A Theory of Insurance Lapses
A Theory of Insurance Lapses
Seth J. Chandler -
 Asylum in the United States
Asylum in the United States
Seth J. Chandler -
 Property Coinsurance
Property Coinsurance
Seth J. Chandler -
 The Persuasion Effect: A Traditional Two-Stage Jury Model
The Persuasion Effect: A Traditional Two-Stage Jury Model
Seth J. Chandler -
 Cellular Automata with Global Control
Cellular Automata with Global Control
Seth J. Chandler -
 Sports Seasons Based on Score Distributions
Sports Seasons Based on Score Distributions
Seth J. Chandler -
 Evidentiary Uncertainty
Evidentiary Uncertainty
Seth J. Chandler -
 Spectral Measures
Spectral Measures
Seth J. Chandler -
 The Banzhaf Power Index of States for Presidential Candidates
The Banzhaf Power Index of States for Presidential Candidates
Seth J. Chandler -
 Liability Insurance Desirability under Lognormal Loss Distributions
Liability Insurance Desirability under Lognormal Loss Distributions
Seth J. Chandler -
 The Effects of Coinsurance and Deductibles on Optimal Precautions for Weibull-Distributed Loss
The Effects of Coinsurance and Deductibles on Optimal Precautions for Weibull-Distributed Loss
Seth J. Chandler -
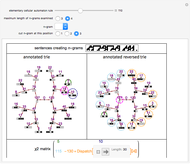 Collocation by Chi Square
Collocation by Chi Square
Seth J. Chandler -
 The Present Value of Future Gas Use
The Present Value of Future Gas Use
Seth J. Chandler -
 Visualizing Legal Rules: A Homicide Case
Visualizing Legal Rules: A Homicide Case
Seth J. Chandler -
Communities of Nations Bridged by Language Similarity
Seth J. Chandler