Fisher Discriminant Analysis




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
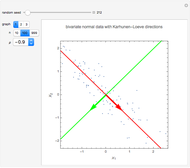
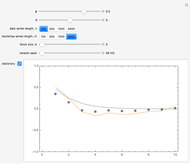
The 30 round points are data. The 15 red points were generated from a normal distribution with mean  , the 15 blue ones with mean
, the 15 blue ones with mean  , and in both cases the covariance matrix was the identity matrix. The problem is to classify or predict the color using the inputs
, and in both cases the covariance matrix was the identity matrix. The problem is to classify or predict the color using the inputs  and
and  .
.


Contributed by: Ian McLeod (March 2011)
Open content licensed under CC BY-NC-SA
Snapshots
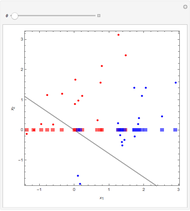
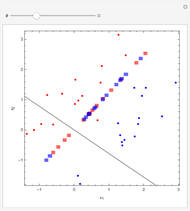
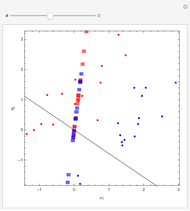
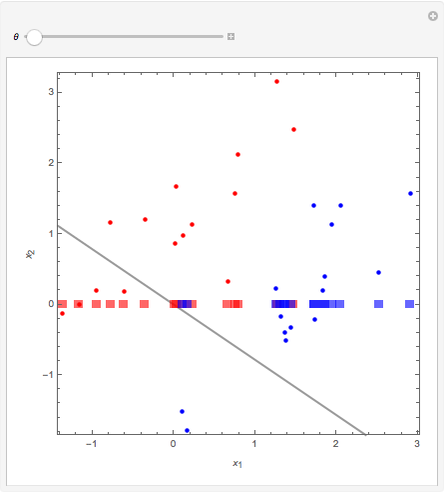


Details
The canonical direction is given by
 ,
,
where  and
and  are the between- and within-classes covariance matrices. Hastie, Tibshirani and Friedman (2009, §4.3.3) [3] show that
are the between- and within-classes covariance matrices. Hastie, Tibshirani and Friedman (2009, §4.3.3) [3] show that  is given by the largest eigenvalue of
is given by the largest eigenvalue of  .
.
The more general case where the number of inputs  is greater than 2 is also considered in [3], but the basic principle of finding the canonical direction is the same. In our illustrative problem we have
is greater than 2 is also considered in [3], but the basic principle of finding the canonical direction is the same. In our illustrative problem we have  inputs as well as
inputs as well as  classes. In general, there are
classes. In general, there are  orthogonal canonical directions with the first canonical direction as defined above. Sometimes, as in [2], it is sufficient just to use just the first canonical component. For extensions, see [3].
orthogonal canonical directions with the first canonical direction as defined above. Sometimes, as in [2], it is sufficient just to use just the first canonical component. For extensions, see [3].
[1] Wikipedia, "Linear Discriminant Analysis."
[2] R. A. Fisher, "The Use of Multiple Measurements in Taxonomic Problems," Annals of Eugenics, 7, 1936 pp. 179–188.
[3] T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed., New York: Springer, 2009.
Permanent Citation
 Principal Components
Principal Components
Ian McLeod Aliasing in Time Series Analysis
Aliasing in Time Series Analysis
Ian McLeod Cluster Analysis for 2D Points
Cluster Analysis for 2D Points
Stephen Wolfram Loading Plot of a Principal Component Analysis (PCA)
Loading Plot of a Principal Component Analysis (PCA)
D. Meliga and S. Z. Lavagnino Exploratory Factor Analysis
Exploratory Factor Analysis
Stuart Nettleton 1, 2, 3-Parameter Logistic Rasch and Birnbaum Models and Item Analysis
1, 2, 3-Parameter Logistic Rasch and Birnbaum Models and Item Analysis
Olexandr Eugene Prokopchenko Exploring Skewness in Box Plots
Exploring Skewness in Box Plots
Ian McLeod Karhunen-Loeve Directions and Regression
Karhunen-Loeve Directions and Regression
Ian McLeod Karhunen-Loeve Directions
Karhunen-Loeve Directions
Ian McLeod Spread-Location Regression Diagnostic Check
Spread-Location Regression Diagnostic Check
Ian McLeod
-
 Rank Transform in Harmonic Regression Time Series
Rank Transform in Harmonic Regression Time Series
Ian McLeod -
 Detecting Periodicity in Short Time Series
Detecting Periodicity in Short Time Series
Ian McLeod -
 Tempered Fractionally Differenced White Noise
Tempered Fractionally Differenced White Noise
Ian McLeod -
 Regression toward the Mean
Regression toward the Mean
Ian McLeod -
Spread-Location Regression Diagnostic Check
Ian McLeod -
 Anscombe Quartet
Anscombe Quartet
Ian McLeod -
 Visualizing Higher-Dimensional Data with 3D Scatterplots
Visualizing Higher-Dimensional Data with 3D Scatterplots
Ian McLeod -
 Mean, Fitted-Value, Error, and Residual in Simple Linear Regression
Mean, Fitted-Value, Error, and Residual in Simple Linear Regression
Ian McLeod -
 Estimating and Diagnostic Checking in Censored Normal Random Samples
Estimating and Diagnostic Checking in Censored Normal Random Samples
Ian McLeod -
 Comparing Gamma and Log-Normal Distributions
Comparing Gamma and Log-Normal Distributions
Ian McLeod -
 Monte Carlo Expectation-Maximization (EM) Algorithm
Monte Carlo Expectation-Maximization (EM) Algorithm
Ian McLeod -
 Comparing Exact and Approximate Censored Normal Likelihoods
Comparing Exact and Approximate Censored Normal Likelihoods
Ian McLeod -
 Transformation to Symmetry of Gamma Random Variables
Transformation to Symmetry of Gamma Random Variables
Ian McLeod -
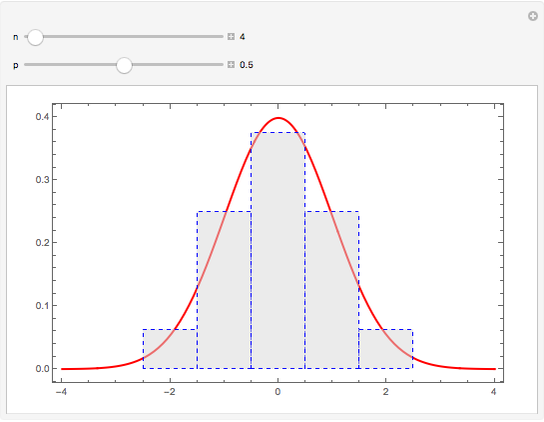 Illustrating the Central Limit Theorem with Sums of Bernoulli Random Variables
Illustrating the Central Limit Theorem with Sums of Bernoulli Random Variables
Ian McLeod -
 Hidden Correlation in Regression
Hidden Correlation in Regression
Ian McLeod -
 Informal Power Assessment of the Normal Probability Plot
Informal Power Assessment of the Normal Probability Plot
Ian McLeod -
 Time Series for Power-Law Decay
Time Series for Power-Law Decay
Ian McLeod -
 Block Bootstrap for Time Series
Block Bootstrap for Time Series
Ian McLeod -
 Fractional Gaussian Noise
Fractional Gaussian Noise
Ian McLeod -
 Plotting a Long Time Series
Plotting a Long Time Series
Ian McLeod