Endogeneity Bias




Requires a Wolfram Notebook System
Interact on desktop, mobile and cloud with the free Wolfram Player or other Wolfram Language products.
Endogeneity is one of the major concerns of contemporary empirical studies in economics and econometrics. This Demonstration aims to show the geometric sense of this phenomenon in the simplest setting, namely the model with one single explanatory variable (also known as the independent variable).
[more]








Contributed by: Timur Gareev (February 2016)
Open content licensed under CC BY-NC-SA
Snapshots
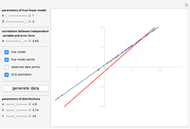
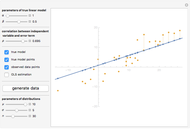
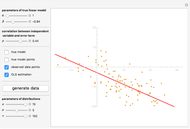
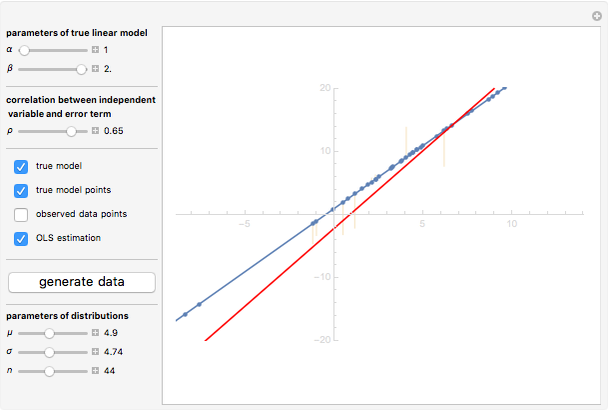
Details
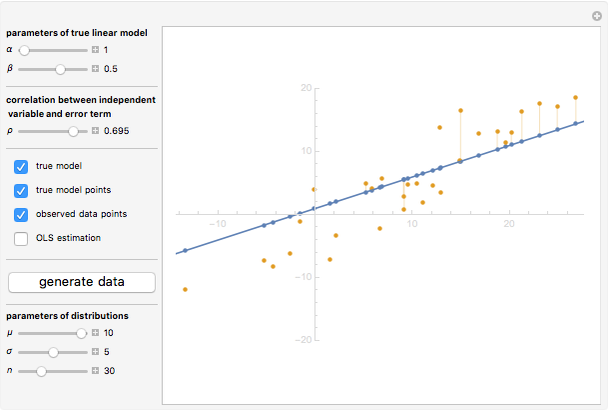
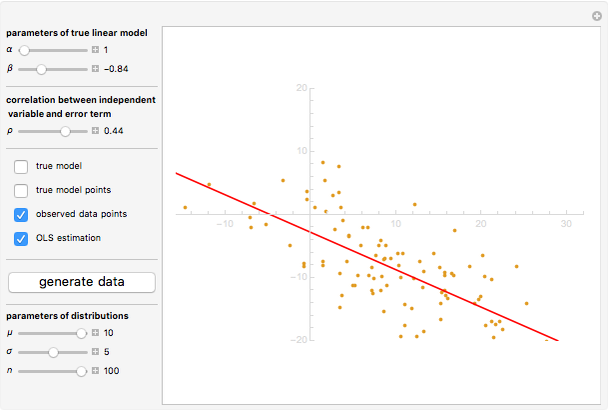
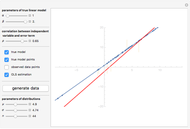
Endogeneity bias (in the narrow sense) is applicable to the model if  . Whenever
. Whenever  (meaning that the independent variable
(meaning that the independent variable  is not correlated with the error term
is not correlated with the error term  ), there is no endogeneity bias (in the narrow sense). In this case, the slope of the fitting curve (OLS regression line) converges to the slope of the true line
), there is no endogeneity bias (in the narrow sense). In this case, the slope of the fitting curve (OLS regression line) converges to the slope of the true line  with the growth of the number of observations
with the growth of the number of observations  , or
, or  .
.
On the contrary, with endogeneity bias there is no such convergence and the fitting model gives inconsistent estimates of in terms of  . You can also see a geometric representation of endogeneity in that simple case when observations (points on the plot) lie systematically lower or higher than a given true line. That is what makes OLS fitting pointless in the presence of endogeneity bias. There are many reasons of endogeneity, namely, omitted variables, measurement errors, and simultaneity. Methods such as using a control function or instrumental variables (IV) can be applied to cure the endogeneity bias problem.
. You can also see a geometric representation of endogeneity in that simple case when observations (points on the plot) lie systematically lower or higher than a given true line. That is what makes OLS fitting pointless in the presence of endogeneity bias. There are many reasons of endogeneity, namely, omitted variables, measurement errors, and simultaneity. Methods such as using a control function or instrumental variables (IV) can be applied to cure the endogeneity bias problem.
This Demonstration is designed to generate random data by clicking the "generate data" button. You can vary the parameters: is the number of observations,  is both (for simplicity of the model) the expectation and the standard error of the random variate
is both (for simplicity of the model) the expectation and the standard error of the random variate  , and
, and  is the standard error of the normally distributed error term
is the standard error of the normally distributed error term  with
with  expectation.
expectation.
Reference
[1] J. M. Wooldridge, Introductory Econometrics: A Modern Approach, Mason, OH: South-Western, Cengage Learning, 2009 p. 26.
Permanent Citation
 Expected Returns of the Dow Industrials, Fama-French Model
Expected Returns of the Dow Industrials, Fama-French Model
Jeff Hamrick and Jason Cawley Mean-Reverting Random Walks
Mean-Reverting Random Walks
Jason Cawley Auto-Regressive Simulation (Second-Order)
Auto-Regressive Simulation (Second-Order)
David von Seggern (University of Nevada) Autoregressive Moving-Average Simulation (First Order)
Autoregressive Moving-Average Simulation (First Order)
David von Seggern (University of Nevada) The Envelope Theorem: Numerical Examples
The Envelope Theorem: Numerical Examples
Jeff Hamrick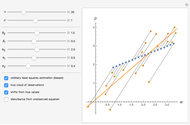 Simultaneity Bias
Simultaneity Bias
Timur Gareev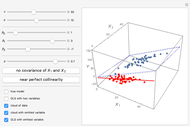 Omitted Variable Bias in 3D
Omitted Variable Bias in 3D
Timur Gareev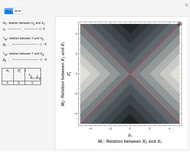 Omitted Variable Bias
Omitted Variable Bias
Alrik Thiem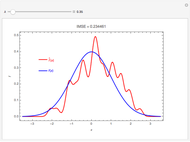 Variance-Bias Tradeoff
Variance-Bias Tradeoff
Ian McLeod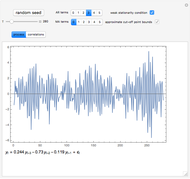 Autoregressive Moving-Average Generator
Autoregressive Moving-Average Generator
Matus Baniar
-
 Returns to Scale in One-Factor Production Functions
Returns to Scale in One-Factor Production Functions
Timur Gareev -
Omitted Variable Bias in 3D
Timur Gareev -
 Revenue and Costs Curves Analysis
Revenue and Costs Curves Analysis
Timur Gareev -
 Leontief Production Function
Leontief Production Function
Timur Gareev -
Simultaneity Bias
Timur Gareev -
 Firm Costs Optimization Problem in Primal and Dual Form
Firm Costs Optimization Problem in Primal and Dual Form
Timur Gareev -
 Comparative and Absolute Advantage
Comparative and Absolute Advantage
Timur Gareev -
 Firm with Two Plants
Firm with Two Plants
Timur Gareev -
 Elasticity Function
Elasticity Function
Timur Gareev -
 Substitute and Complementary Goods
Substitute and Complementary Goods
Timur Gareev -
 Monopoly with Two Plants
Monopoly with Two Plants
Timur Gareev -
 Best Response in Static Two-Player Games
Best Response in Static Two-Player Games
Timur Gareev -
 Hotelling Model of Product Quality Differentiation
Hotelling Model of Product Quality Differentiation
Timur Gareev -
 Endogeneity Bias
Endogeneity Bias
Timur Gareev -
 Discriminating Monopolist with Two Independent Markets
Discriminating Monopolist with Two Independent Markets
Timur Gareev -
 Monopsony in the Labor Market
Monopsony in the Labor Market
Timur Gareev -
 Nondiscriminating Monopolist with Two Independent Markets
Nondiscriminating Monopolist with Two Independent Markets
Timur Gareev -
 Supply Curve from Piecewise Linear Cost Function
Supply Curve from Piecewise Linear Cost Function
Timur Gareev -
 Duopoly Model in 3D
Duopoly Model in 3D
Timur Gareev -
 Isocosts, Isoquants, Isocline Lines, and Scale Lines for Homogeneous (Cobb-Douglas) Functions
Isocosts, Isoquants, Isocline Lines, and Scale Lines for Homogeneous (Cobb-Douglas) Functions
Timur Gareev